🚀 1,000+ TOKENS/S ON A 1T MODEL! 🚀 We are thrilled to release Xiaomi MiMo-V2.5-Pro-UltraSpeed in collaboration with @TileRT_AI , breaking the 1,000 tokens/s output speed on a 1 Trillion parameter model for the FIRST TIME! Not wafer-scale integration like Cerebras. Not pure on-chip SRAM chips like Groq. We achieve 1,000 tps on a 1T MoE model using just a SINGLE, STANDARD 8-GPGPU NODE. Read the full technical deep dive:https://t.co/MX0kjHKdKi Want to experience the future of real-time AI? 👉 Apply for UltraSpeed now: https://t.co/aeWAxyhwVk ⏳ Limited-Time Access: Application-based · Jun 8 – Jun 23 (PDT) 💬 Chat Experience: Completely FREE for a limited time — try the blazing-fast web chat now. ⚡ UltraSpeed API: Just 3x the price for a ~10x boost in output experience. 🤝 Enterprise & Large-Scale Needs: business-mimo@xiaomi.com
Xiaomi MiMo Breaks 1,000 Tokens/s on 1T Model with Standard GPUs
· Updated
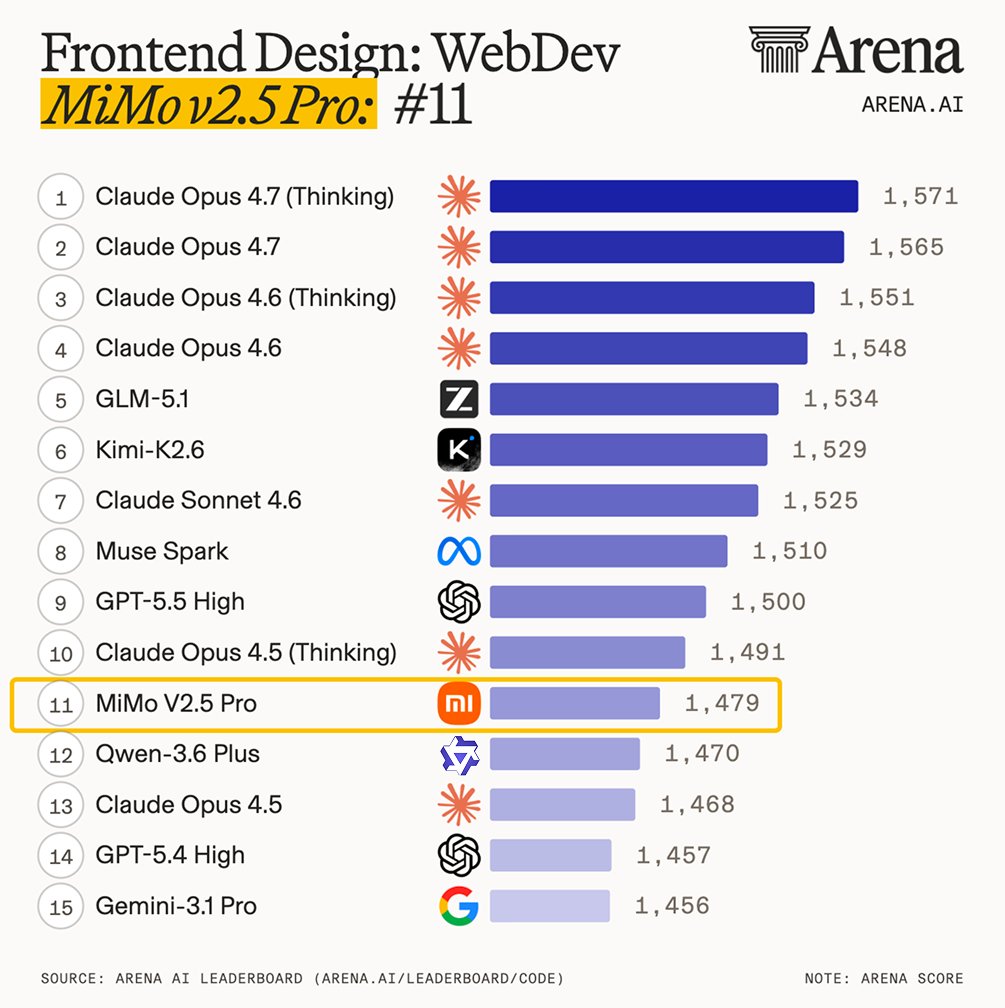
Xiaomi MiMo, in collaboration with TileRT, released MiMo-V2.5-Pro-UltraSpeed, achieving over 1,000 tokens/s output speed on a 1-trillion-parameter model using a single standard 8-GPU node. This breakthrough enables real-time AI applications and faster agentic coding by overcoming inference speed bottlenecks on commodity hardware.
- Output Speed
- 1,000+ tokens/s
- Model Parameters
- 1 trillion (1T)
- Hardware
- Single, standard 8-GPU node
- API Pricing
- 3x cost for ~10x speed boost
- Access Window
- June 9 – June 23, 2026 (PDT)
- Open-Source Checkpoint
- MiMo-V2.5-Pro-FP4-DFlash
This makes 1T models viable for real-time decision loops — high-frequency trading, anti-fraud, and surgical assistance — and removes inference latency as a bottleneck for agentic coding workflows. For comparison, DeepSeek V4 Pro reaches 150+ tps and Nemotron 3 Ultra 300+ tps.
Available in a limited window from June 9–23, 2026 (PDT), MiMo-V2.5-Pro-UltraSpeed offers free chat and an API at 3x the standard MiMo-V2.5-Pro price for ~10x the generation speed. The MiMo-V2.5-Pro-FP4-DFlash checkpoint is open-sourced on HuggingFace.
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →