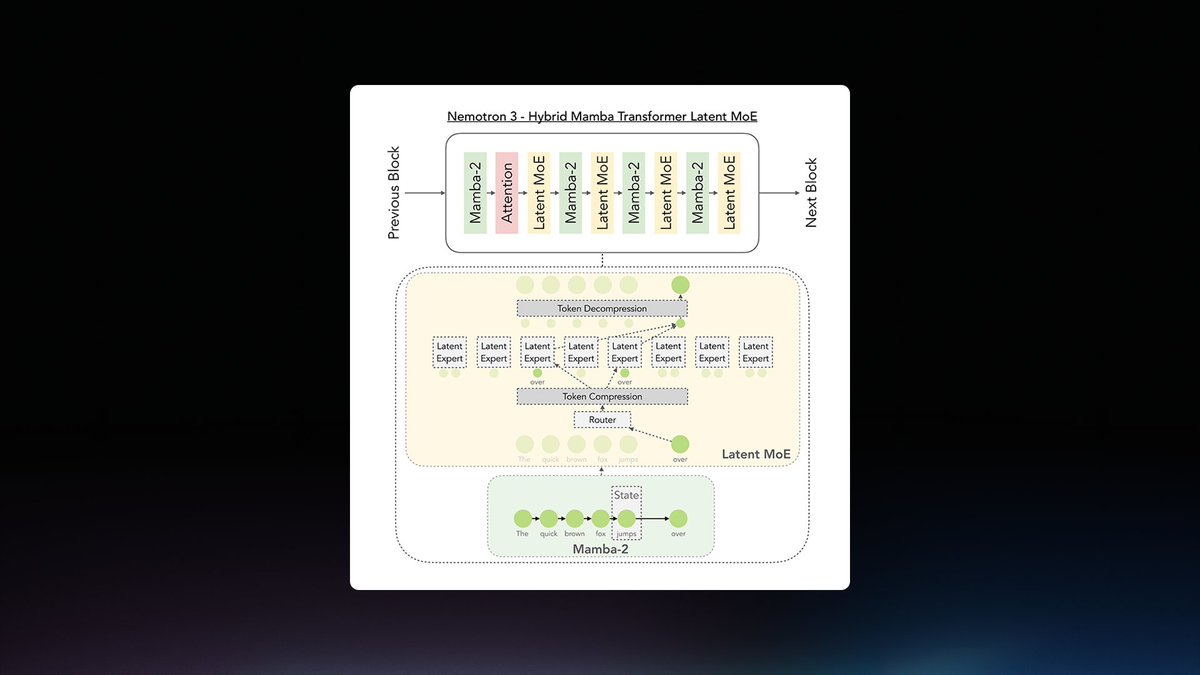
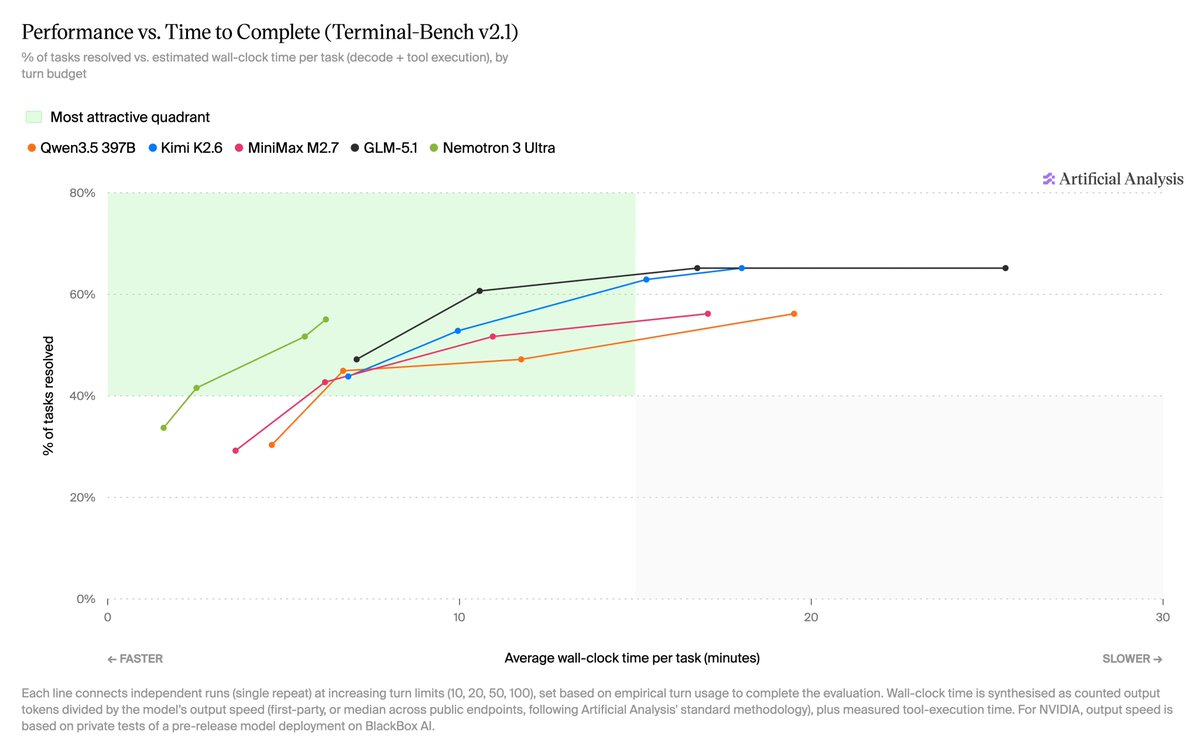
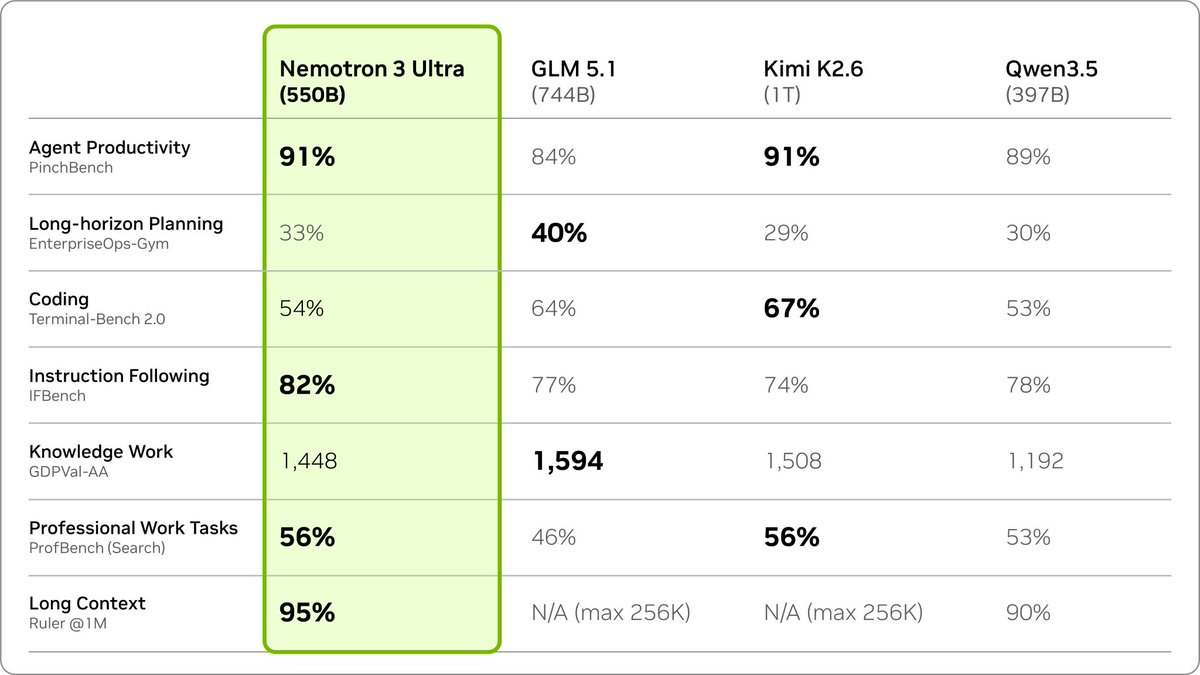
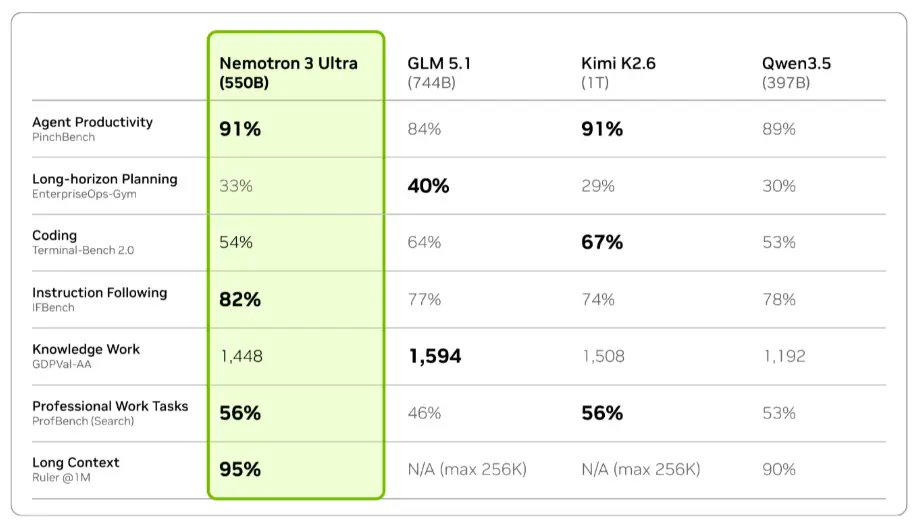
NVIDIA just announced the release of Nemotron 3 Ultra in Jensen Huang's Computex keynote: at 550B parameters (55B active), this is the largest Nemotron 3 model to date, and it is the most intelligent US open weights model We partnered with @nvidia to evaluate this model for intelligence and speed - these figures use the model’s BF16 weights, but as with Nemotron 3 Super the model will be made available in NVFP4 quantization as well for higher inference performance. ➤ New leader for US open weights intelligence: Nemotron 3 Ultra scores 48 on the Artificial Analysis Intelligence Index. This is well ahead of the next strongest US open weights models, Gemma 4 31B (39), Nemotron 3 Super (36) and gpt-oss-120b (33), but behind the Chinese-led open weights frontier (Kimi K2.6 at 54). ➤ Leading speed for its intelligence: on a pre-release @DeepInfra endpoint, Nemotron 3 Ultra served over 300 tokens per second. Peer models in its size class from China-based labs such as DeepSeek and Moonshot (Kimi) are generally served at speeds of 50-100 tokens per second in the market today. gpt-oss-120b is served at speeds similar to this level, but with significantly lower intelligence. ➤ Largest Nemotron 3 model so far: at approximately 550 billion total parameters and 90% sparsity, Nemotron 3 Ultra is significantly larger than its siblings and is the largest recent US open weights model release We’ll be sharing additional analysis and full benchmarks at release.
NVIDIA Nemotron 3 Ultra Claims Top US Open Weights Intelligence Spot
· Updated
NVIDIA released Nemotron 3 Ultra, a 550B-parameter model that leads US open-weights benchmarks with an intelligence score of 48. The model delivers high-throughput performance exceeding 300 tokens per second, significantly outpacing similarly sized frontier models from China.
- Total Parameters
- 550B
- Active Parameters
- 55B
- Intelligence Index Score
- 48
- Inference Speed
- 300+ tokens per second
- Sparsity
- 90%
This release shifts the open-weights landscape, unseating Gemma 4 31B as the previous US intelligence leader. While it trails the Chinese frontier, it maintains a massive speed advantage. It serves over 300 tokens per second, outpacing international peers like Kimi K2.6 by 3x.
The model extends the family introduced in the Nemotron 3 launch and follows the Nemotron 3 Super launch. It accompanies the NVIDIA Cosmos 3 release and is available in BF16 weights, with NVFP4 quantization—a compression method to speed up inference—coming soon. Artificial Analysis benchmarked the model on a pre-release DeepInfra endpoint.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →