NVIDIA has shipped Nemotron 3 Ultra, a 550B Mixture-of-Experts (MoE) open model designed for long-running AI agents. This model delivers 5x faster inference and up to 30% lower cost for complex agentic tasks compared to other open frontier models, aiming to make autonomous workflows more efficient and accessible.
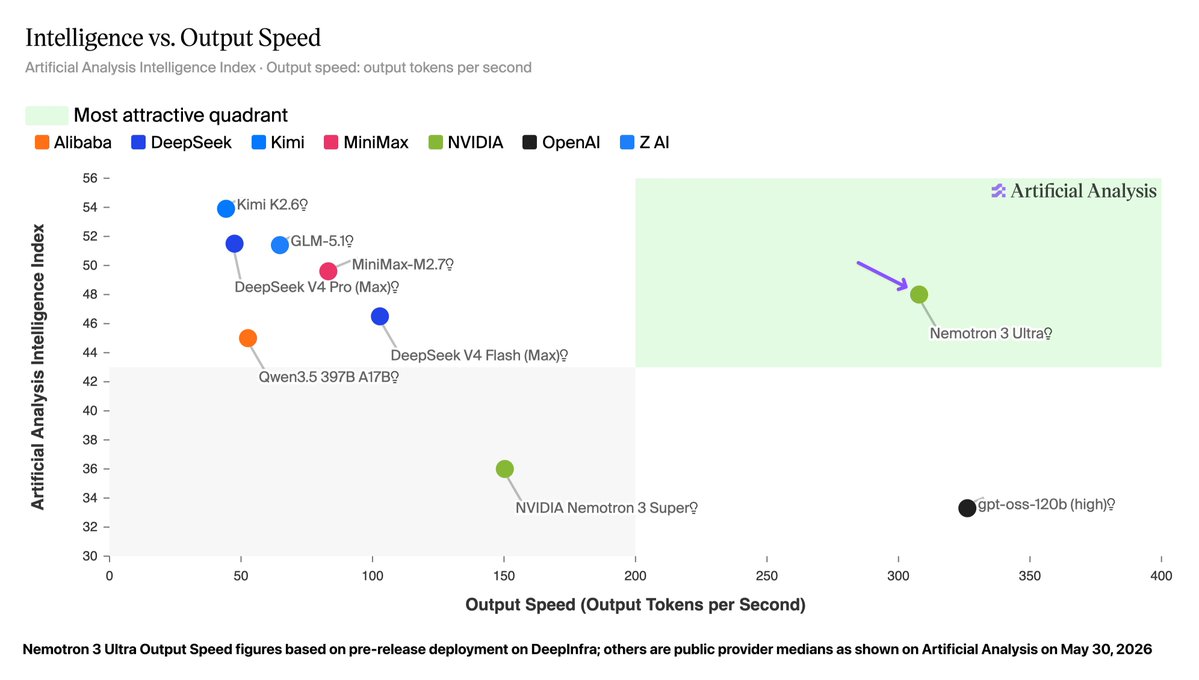
NVIDIA has shipped Nemotron 3 Ultra, a 550B-parameter Mixture-of-Experts (MoE) model with 55B active parameters, built for long-running AI agents. This open model delivers 5x faster inference (running a trained AI model) and up to 30% lower cost for complex agentic tasks.
- Total Parameters
- 550B
- Active Parameters
- 55B
- Inference Speed
- 5x faster vs. other open frontier models
- Cost Reduction
- Up to 30% lower for agentic tasks
- Architecture
- Hybrid Mamba-Transformer MoE
- Licensing
- OpenMDW-1.1
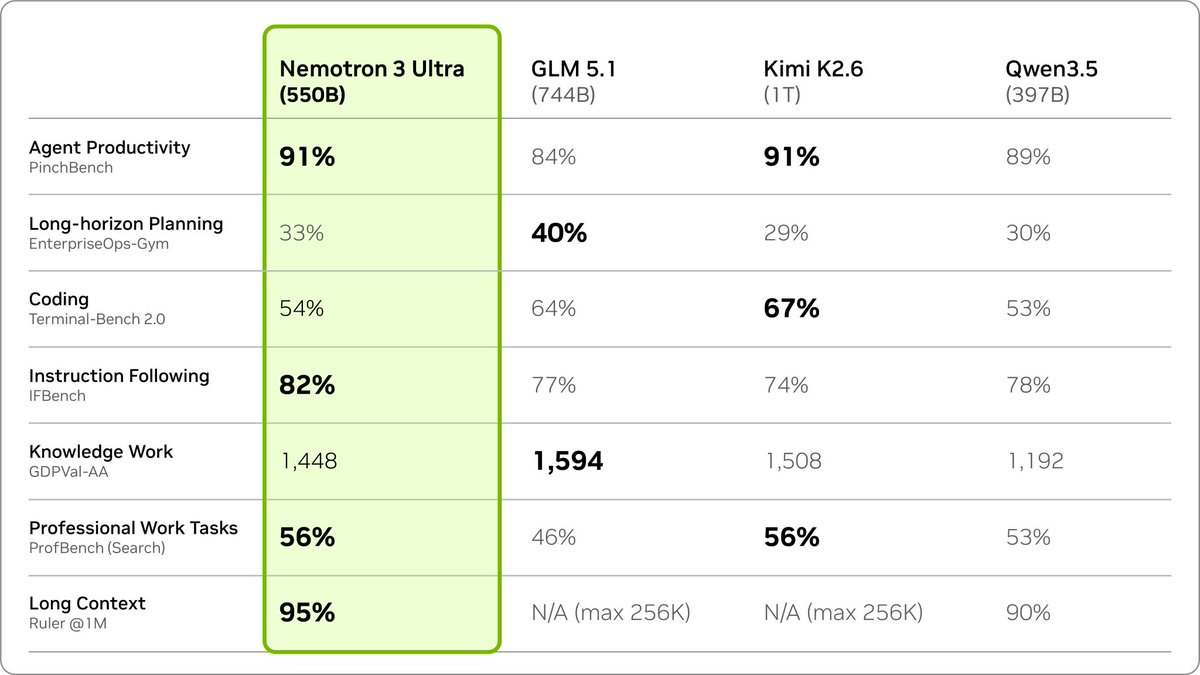
Its hybrid Mamba-Transformer MoE architecture enables more reasoning cycles within the same time budget, addressing multi-agent workflow challenges. It achieves leading accuracy for agent productivity, coding, and long-horizon planning, supporting large codebases and synthesizing hundreds of sources.
Nemotron 3 Ultra is fully open, including weights and training recipes, and is post-trained for popular agent harnesses. It is available on Hugging Face and various inference platforms, alongside new Nemotron 3.5 Content Safety and Nemotron 3.5 ASR models for guardrails and multilingual voice.