NVIDIA has released Nemotron 3 Ultra, an open model designed for long-running AI agents, and provided a tutorial for its setup and demonstrations. This model aims to make complex, multi-step agentic workflows faster and more cost-effective by delivering high throughput and efficient reasoning.
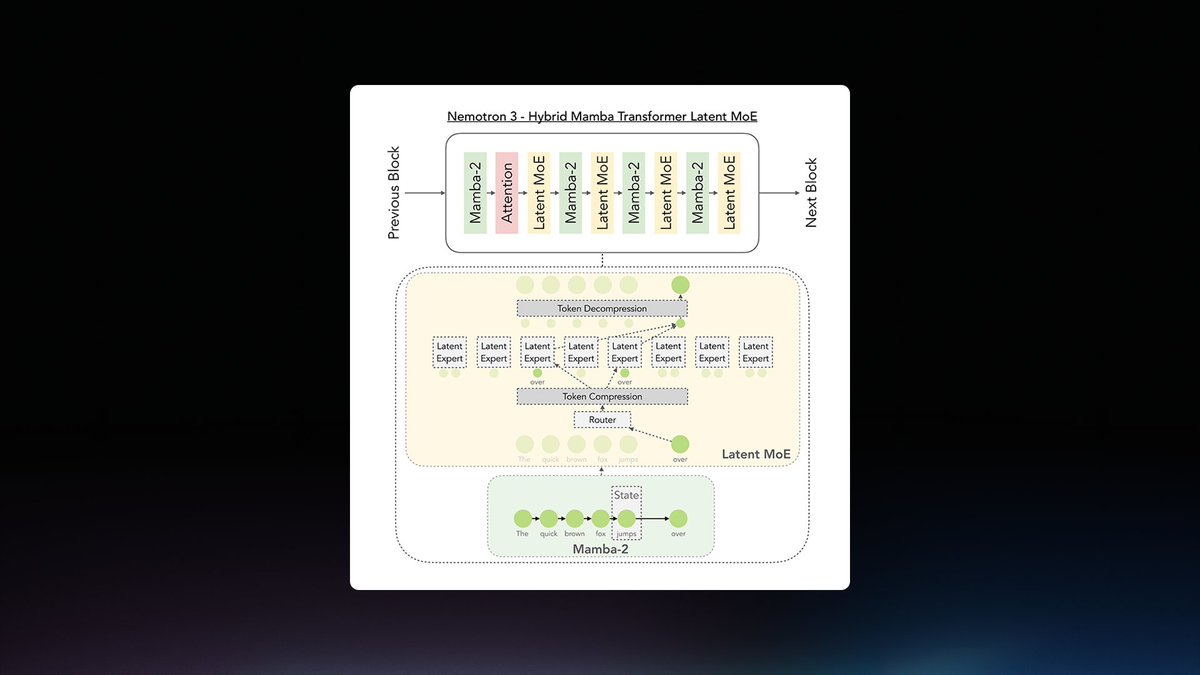
NVIDIA has released Nemotron 3 Ultra, an open 550B-parameter Mixture-of-Experts (MoE) model with 55B active parameters, optimized for agent orchestration and reasoning in long-running AI agent workflows. It is post-trained for agent harnesses, enabling multi-turn planning, tool use, and error recovery, integrating Hybrid Mamba-Transformer layers for efficient long-context handling.
- Total Parameters
- 550B
- Active Parameters
- 55B
- Inference Throughput
- Up to 5x higher
- Cost Reduction for Agentic Tasks
- Up to 30%
- Licensing
- OpenMDW-1.1
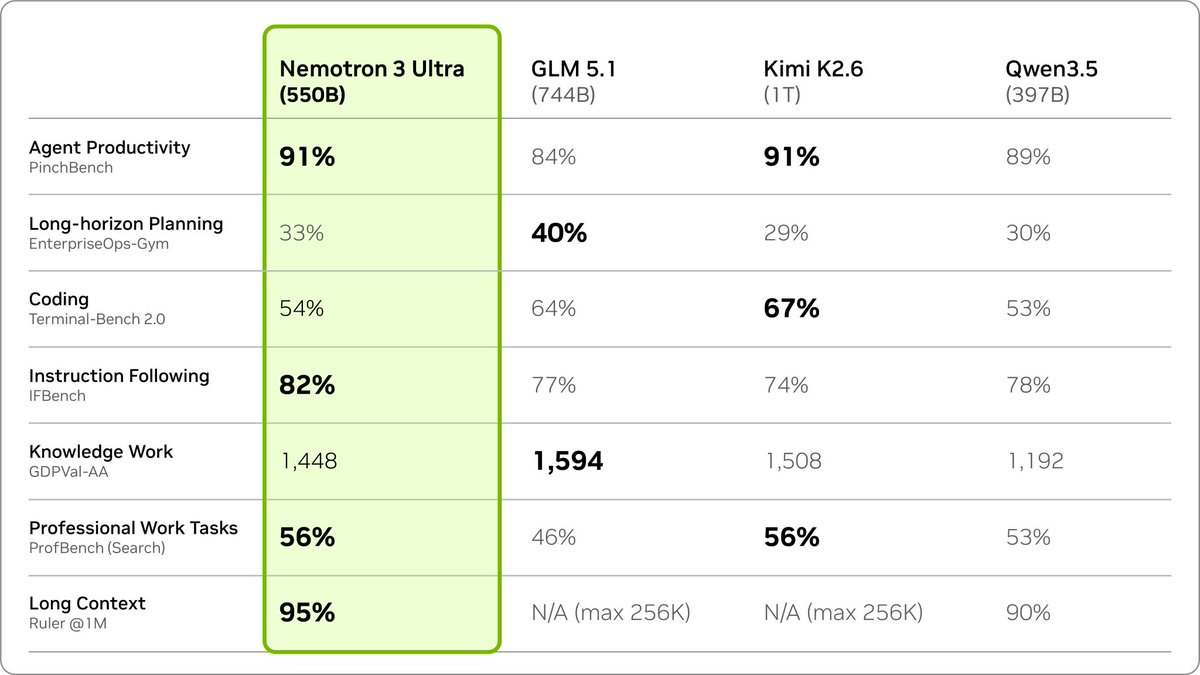
This model addresses challenges in multi-agent systems where token counts and costs grow quickly. Nemotron 3 Ultra delivers up to 5x higher throughput and can lower the cost for agentic tasks by up to 30% compared to other open models, making autonomous workflows more efficient.
Nemotron 3 Ultra ships with open weights, data, and recipes under the OpenMDW-1.1 license, the work of the NVIDIA Nemotron Coalition. It's already on Perplexity Pro, OpenRouter, and Hugging Face, and plugs into agent frameworks like Hermes Agent and OpenCode.