Ollama has made NVIDIA's Nemotron 3 Ultra model available on its cloud. This 550 billion parameter Mixture of Experts (MoE) model is designed for long-running AI agents, delivering 5x faster inference and up to 30% lower costs for complex agentic tasks.
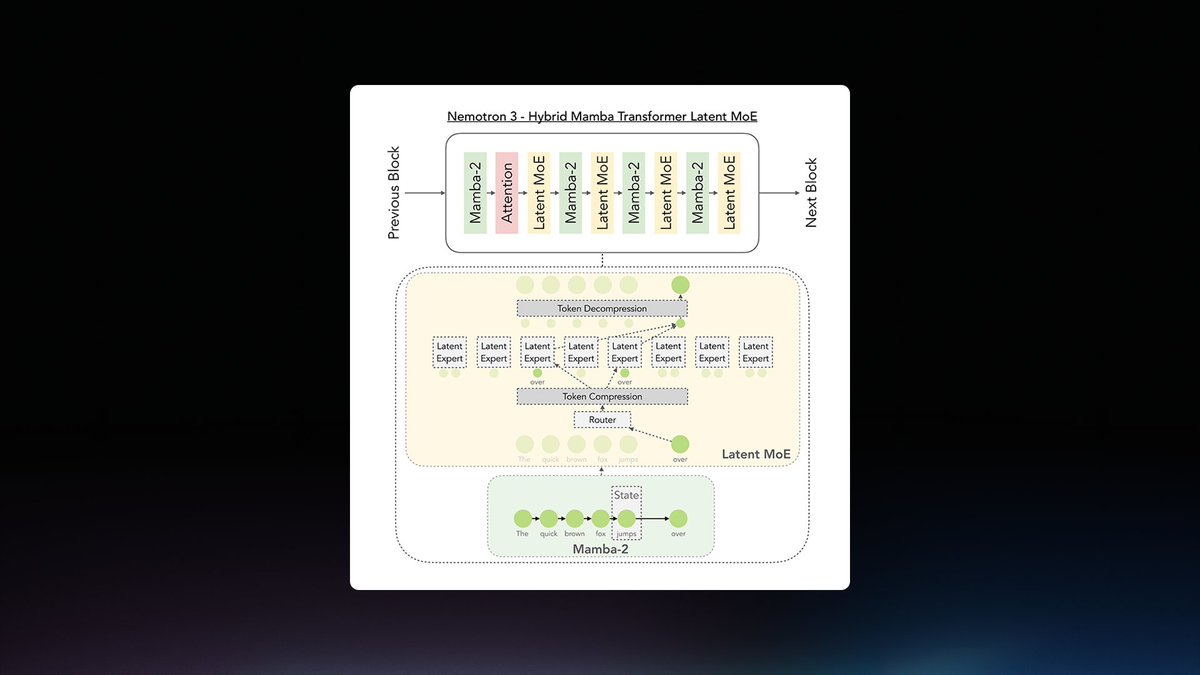
Ollama now hosts NVIDIA Nemotron 3 Ultra, a 550 billion parameter (55B active) open model, on its cloud. This Mixture of Experts (MoE) (an architecture using multiple specialized sub-networks) model is built for high-throughput reasoning and long-running agent workflows, supporting a 1 million token context window.
- Cloud Model
- nemotron-3-ultra:cloud
- Agentic Tools
- Claude Code, Hermes Agent, OpenClaw
- Access
- ollama launch (agents), ollama run (chat)
The model is optimized for NVIDIA's 4-bit floating point format (NVFP4), enabling 5x faster inference and up to 30% lower costs for complex agentic tasks compared to other open frontier models. Nemotron 3 Ultra leads on agent productivity, instruction following, and long-context benchmarks.
Nemotron 3 Ultra is accessible via Ollama's cloud for general chat and integrates with agentic coding tools like Claude Code, Hermes Agent, and OpenClaw. You can launch these applications with the model using simple ollama launch commands, enabling access to advanced agentic capabilities via Ollama's cloud.