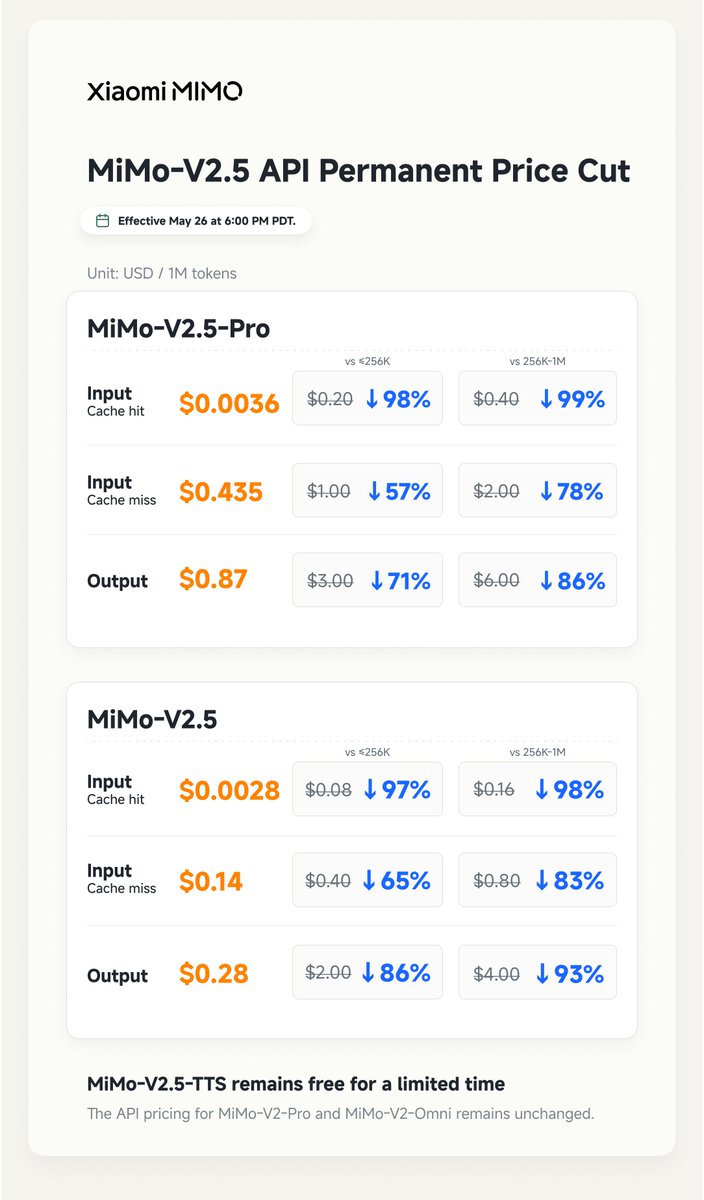
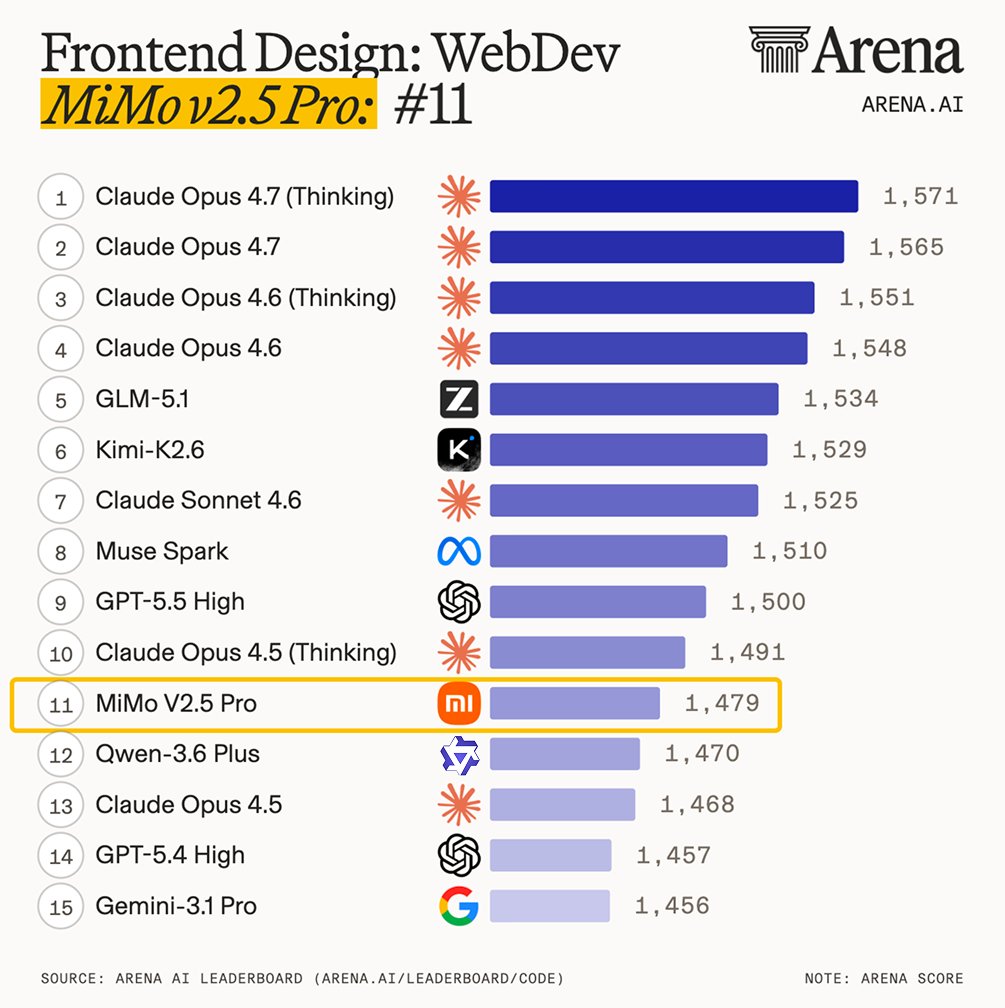
Xiaomi MiMo
@XiaomiMiMo
What’s new with MiMo-V2.5 series inference? We just published a blog on our full pipeline inference optimizations for MiMo-V2.5 series, including how we pushed hybrid SWA efficiency to the limit. Read the full blog here: https://t.co/lYBEcgaVhU
31retweets375likes
View on X