Qwen
@Alibaba_Qwen
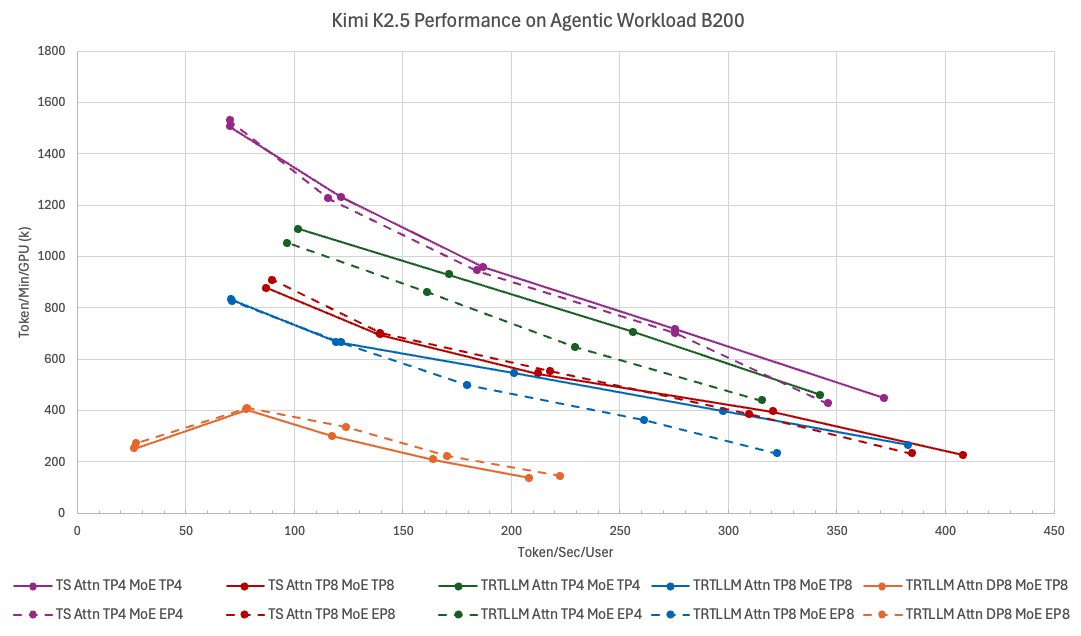
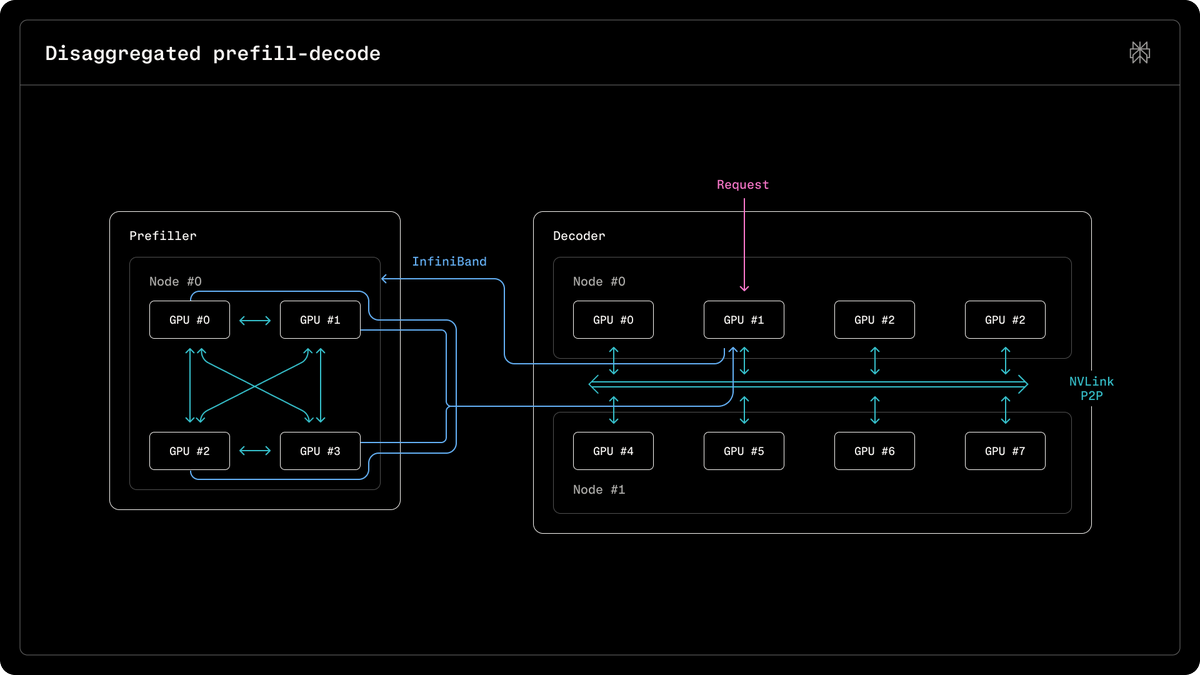
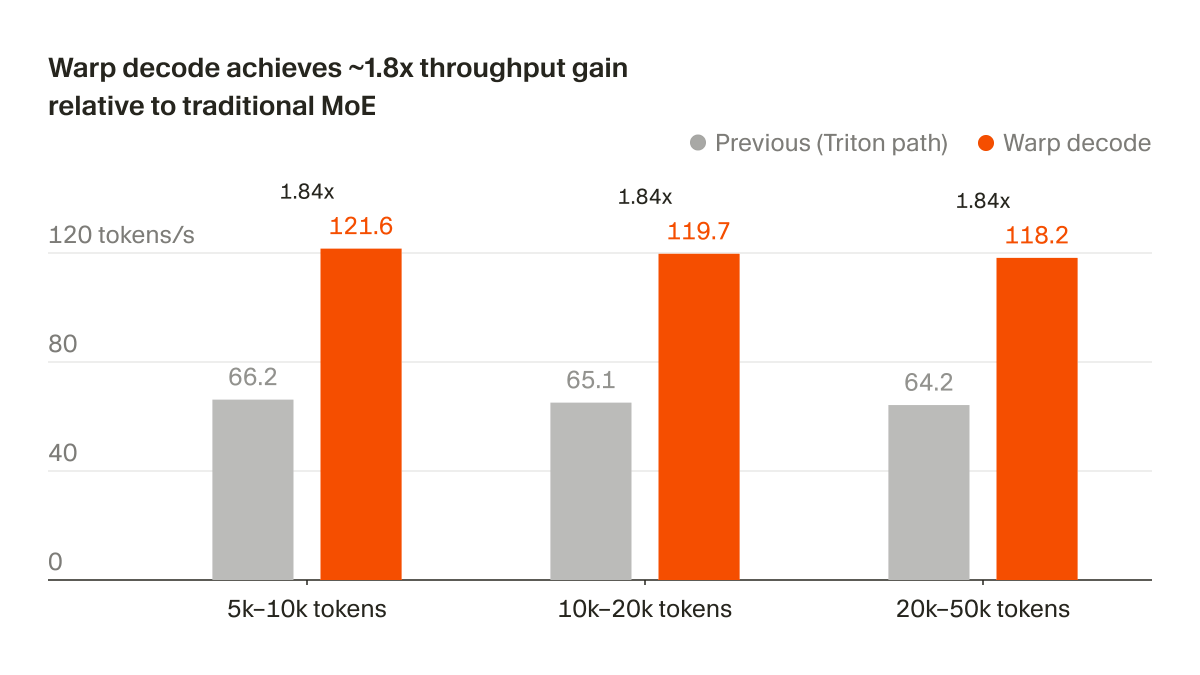
Fast, faster, Qwen. 🚀 Thrilled to see Qwen3.5 reaching a record-breaking 580 tps for agentic workloads on the TokenSpeed engine! This milestone wouldn't be possible without our incredible partners. Huge thanks to @lightseekorg, @NVIDIAAI, the Mooncake team, and @tri_dao for the pioneering FA4 optimization. Together, we are pushing the boundaries of open-source LLM inference. 🤝✨ Dive into the full @PyTorch blog post below! 👇 https://t.co/p04wookcZj #Qwen #Qwen3_5 #TokenSpeed #LLM #Inference #AI #PyTorch #OpenSource #AgenticAI #HighPerformance
83retweets963likes
View on X