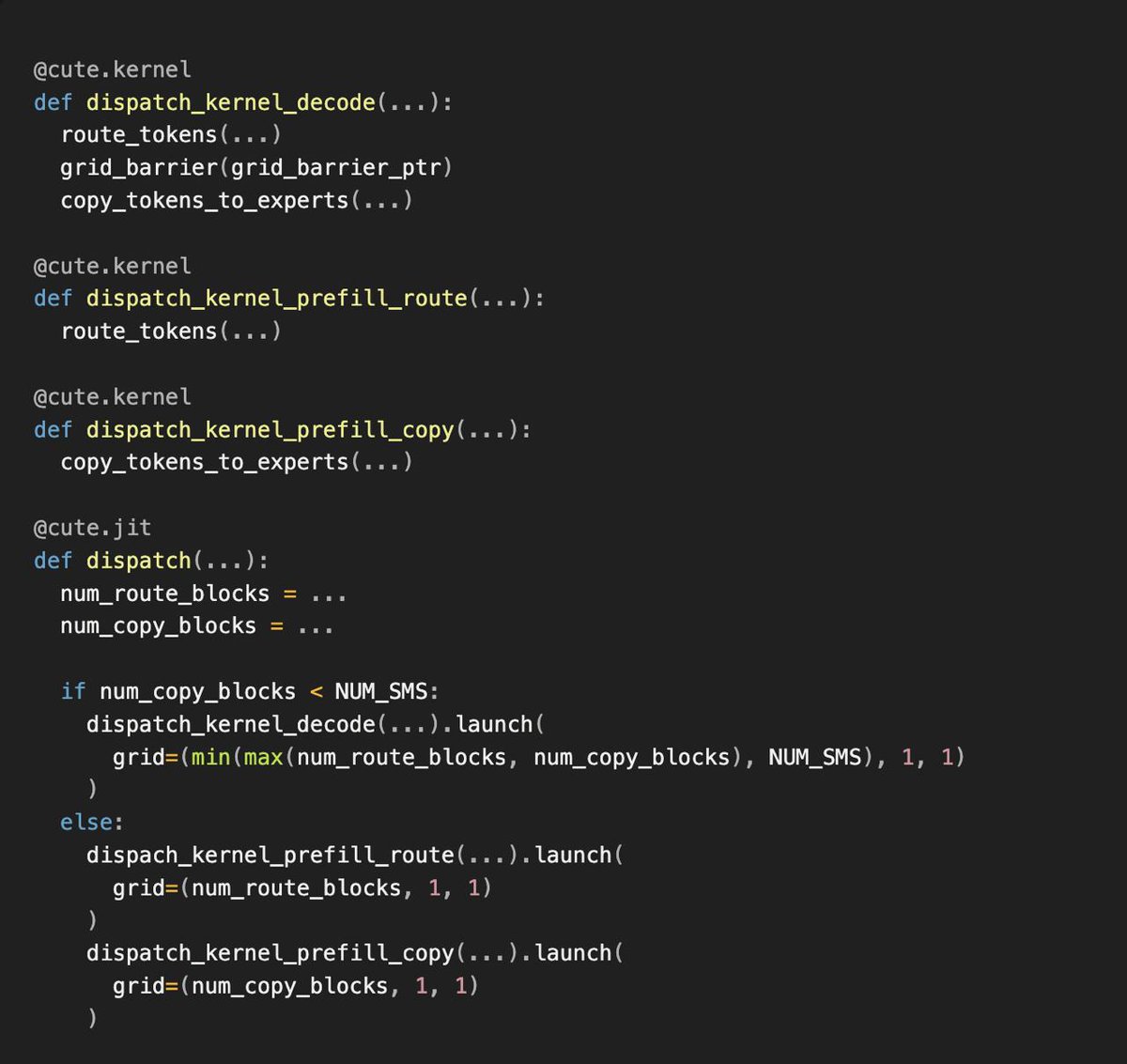
LightSeek Foundation released TokenSpeed, an open-source inference engine designed specifically for the long-context and high-throughput demands of AI coding agents. By optimizing kernels for NVIDIA Blackwell hardware, the system achieves higher performance than TensorRT-LLM on agentic benchmarks while maintaining the usability of vLLM.
LightSeek Foundation, a Silver Member of the PyTorch Foundation, introduced TokenSpeed in a performance preview. It is an MIT-licensed inference engine (software that runs trained AI models) built for the unique traffic patterns of autonomous agents. The system uses a compiler-backed modeling layer to automate parallel operations.
- Throughput gain
- 11% higher than TensorRT-LLM
- Latency reduction
- Nearly 50% for decode workloads
- Hardware support
- NVIDIA Blackwell B200
- License
- MIT
- Availability
- Performance preview on GitHub
Standard engines are often optimized for general chat, but agentic workloads (tasks where AI agents plan and act independently) require responsiveness across contexts exceeding 50,000 tokens. TokenSpeed targets this gap by outperforming TensorRT-LLM on Blackwell hardware, delivering 11% higher throughput. This mirrors Perplexity's ROSE engine and NVIDIA Dynamo optimizations.
Access the source code on GitHub to run models like DeepSeek V4 with optimized attention kernels already being adopted by vLLM. Production hardening is planned for next month. The project is a collaboration including engineers from NVIDIA, AMD, and Alibaba's Qwen team.