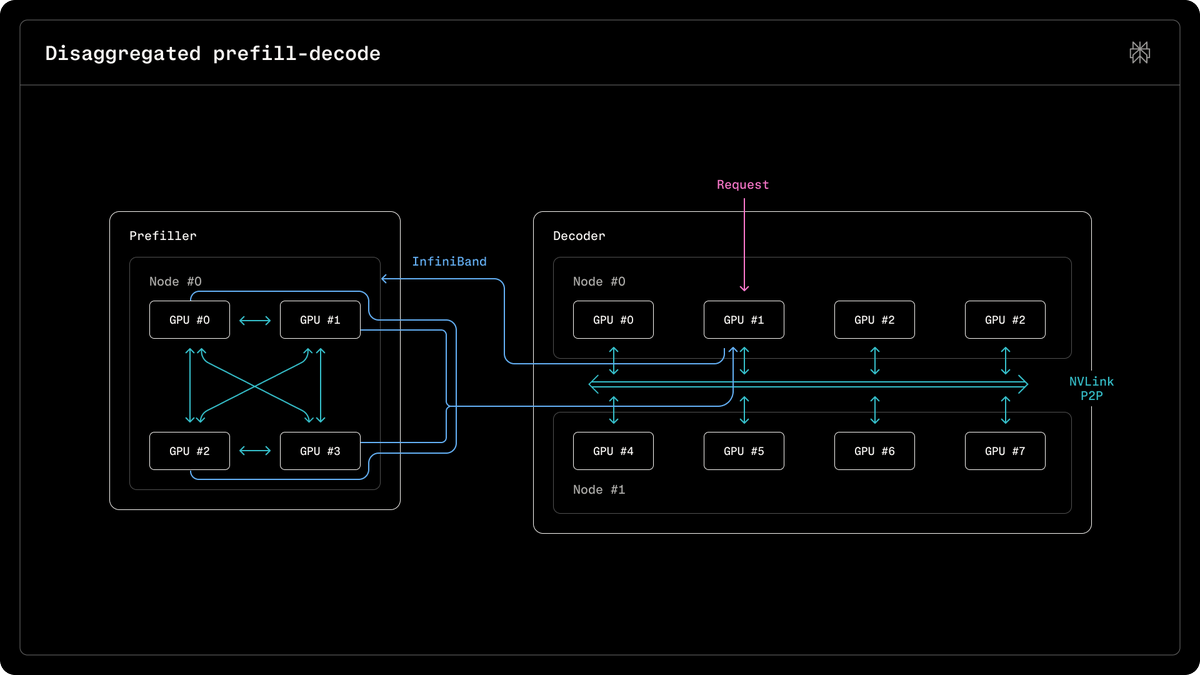
Perplexity developed a custom inference engine called ROSE and a domain-specific language to build specialized GPU kernels for NVIDIA hardware. By moving down the stack, the company can achieve peak performance on Blackwell chips and reduce latency for massive trillion-parameter models.
Perplexity, an AI-powered answer engine, developed its own inference engine (the process of running a trained model to generate outputs) called ROSE. The Runtime-Optimized Serving Engine handles models ranging from embeddings to trillion-parameter LLMs. It integrates CuTeDSL, a domain-specific language that accelerates the creation of specialized GPU kernels.
- Inference engine
- ROSE
- Kernel language
- CuTeDSL
- Target hardware
- NVIDIA Hopper and Blackwell GPUs
- Model capacity
- Up to trillion-parameter LLMs
- Research focus
- Search, reasoning, agents, and systems
This shift toward custom infrastructure allows Perplexity to bypass generic libraries and tune directly for NVIDIA Hopper and Blackwell architectures. It mirrors industry trends where companies launch NVIDIA Dynamo 1.0 to act as an inference operating system. By owning the kernel layer, Perplexity can squeeze peak performance from the latest hardware.
While this is an internal update, it provides the technical foundation for the platform's complex Perplexity search agent research and follows the release of Perplexity Finance Search for developers. You will likely see lower latency across Perplexity’s Pro and Max tiers as these optimizations roll out. The research team plans to continue advancing their mission through frontier systems research.