Perplexity published research showing that NVIDIA's GB200 Blackwell architecture nearly halves communication latency for large Mixture-of-Experts models compared to the previous generation. The findings suggest that Blackwell is a primary platform for reducing the cost and latency of serving frontier-scale AI search.
Perplexity, an AI-powered answer engine providing real-time cited responses, published research on serving Qwen3 235B on NVIDIA GB200 NVL72 Blackwell racks. Blackwell is a major upgrade over Hopper for high-throughput inference (running a trained model to generate outputs) on large Mixture-of-Experts (MoE) models (AI models that activate only a fraction of their parameters).
- All-reduce latency (H200)
- 586.1 microseconds
- All-reduce latency (GB200)
- 313.3 microseconds
- MoE prefill latency (H200)
- 730.1 microseconds
- MoE prefill latency (GB200)
- 438.5 microseconds
- Model tested
- Qwen3 235B
- Hardware
- NVIDIA GB200 NVL72 Blackwell
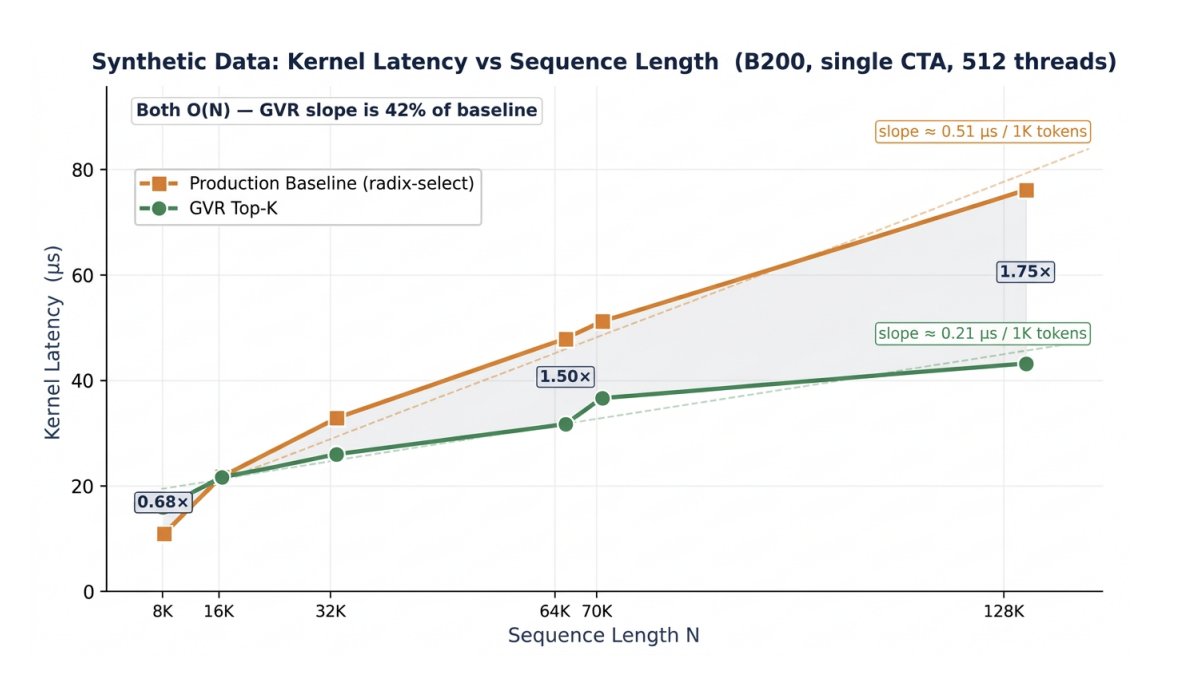
Benchmarks reveal Blackwell's rack-scale NVLink architecture addresses the primary bottleneck for massive MoE models: data-shuffling latency between GPUs. By nearly halving all-reduce latency, Perplexity can deliver faster answers at lower cost. This follows the development of Perplexity's ROSE inference engine to optimize Blackwell hardware.
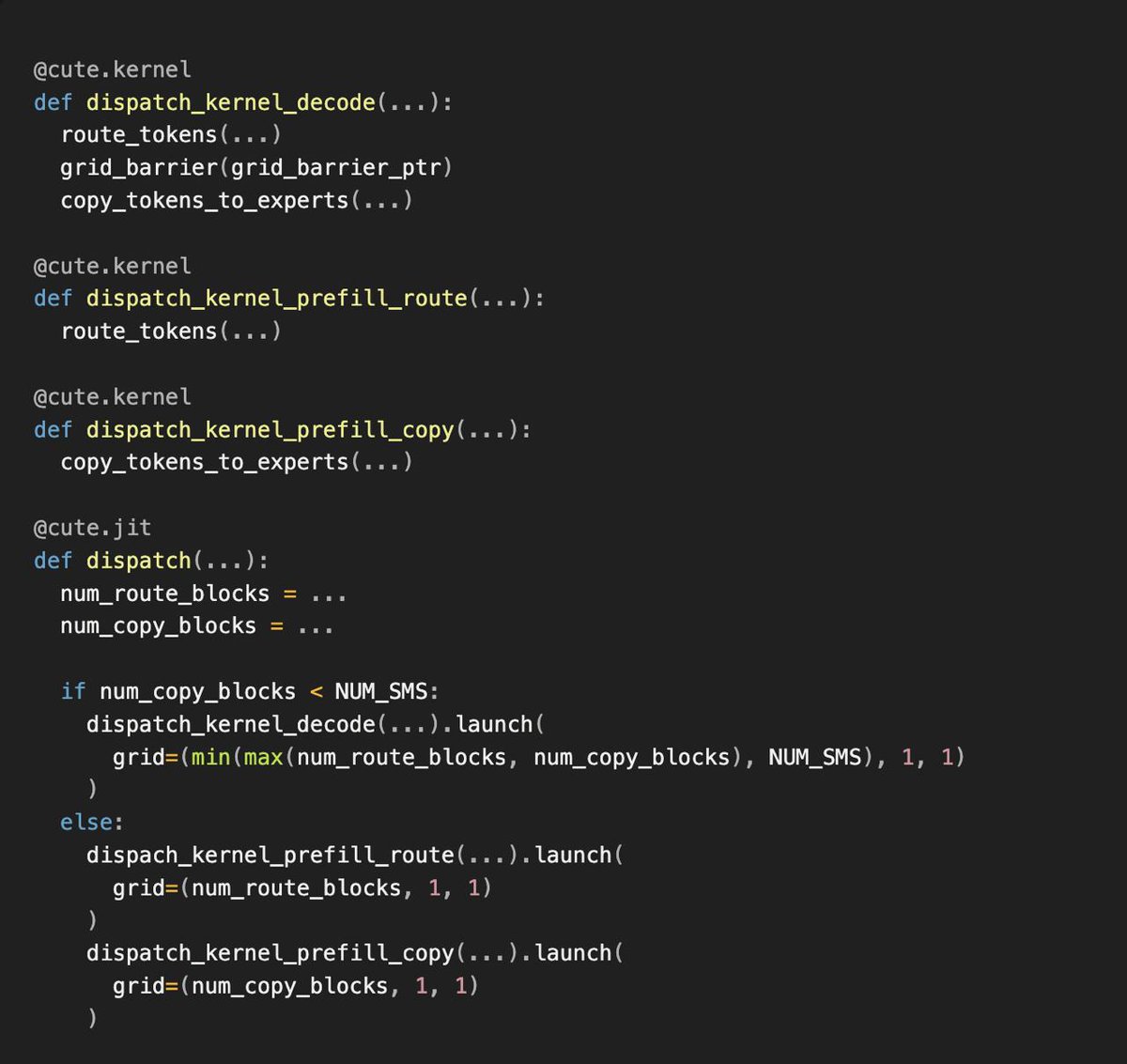
For organizations deploying trillion-parameter models, these results validate the shift toward prefill/decode disaggregation and Blackwell-native quantization. While the research focuses on internal infrastructure, it signals a broader industry move toward Blackwell-optimized inference paths. Review the full technical paper for specific kernel optimizations.