Nebius secured 10 first-place finishes in the MLPerf Inference v6.0 benchmarks using the latest NVIDIA Blackwell and Blackwell Ultra systems. These results demonstrate linear performance scaling for frontier models like DeepSeek R1, providing a verified blueprint for high-throughput production AI infrastructure.
Nebius submitted results for the MLPerf Inference v6.0 suite, testing the latest NVIDIA Blackwell and Blackwell Ultra architectures. The submission covered the HGX B200, HGX B300, and the rack-scale GB300 NVL72 system. Benchmarks focused on frontier-scale models including DeepSeek R1, the multimodal Qwen3-VL 235B, and gpt-oss 120B.
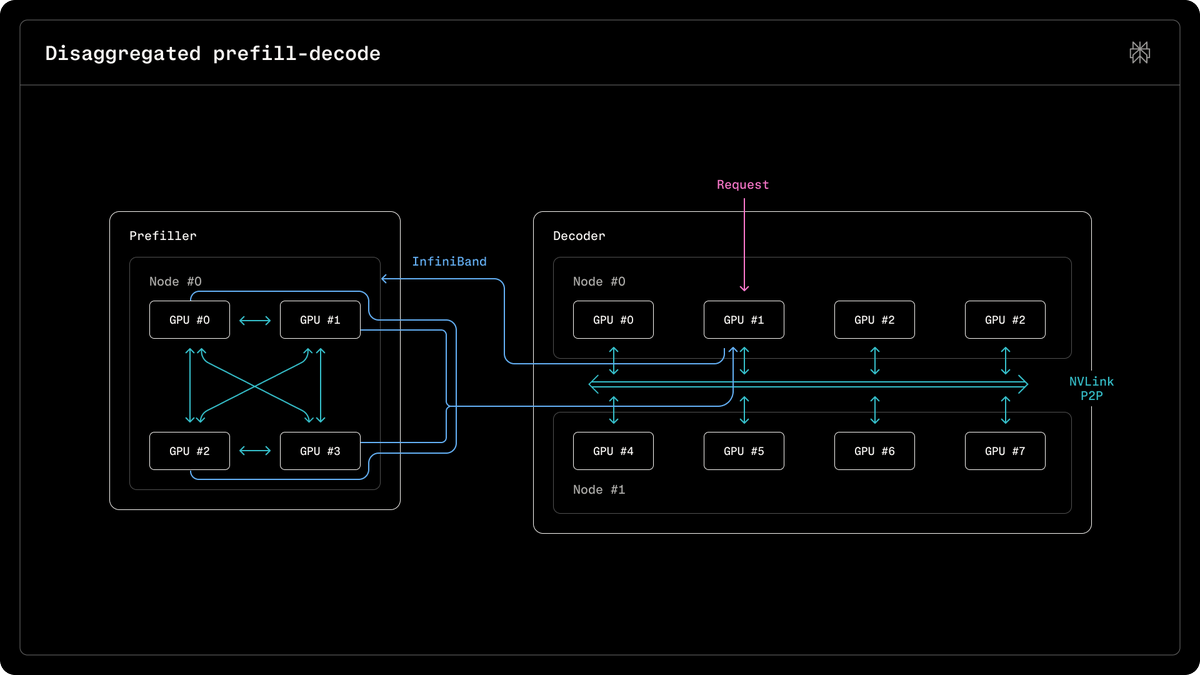
As the industry shifts toward reasoning models and multimodal systems, raw hardware access is no longer enough. These results prove that Nebius has optimized its networking and software stack to extract maximum throughput from NVIDIA's newest silicon. The GB300 NVL72 configuration demonstrated linear scaling across 72 GPUs, ensuring performance does not degrade at scale.
You can now leverage these optimized configurations for latency-sensitive applications like agentic loops. Nebius provides these capabilities through its AI cloud platform and the Nebius Token Factory. If you are scaling production deployments of DeepSeek R1, these benchmarks offer a verified baseline for expected tokens-per-second performance.