NVIDIA AI
@NVIDIAAI
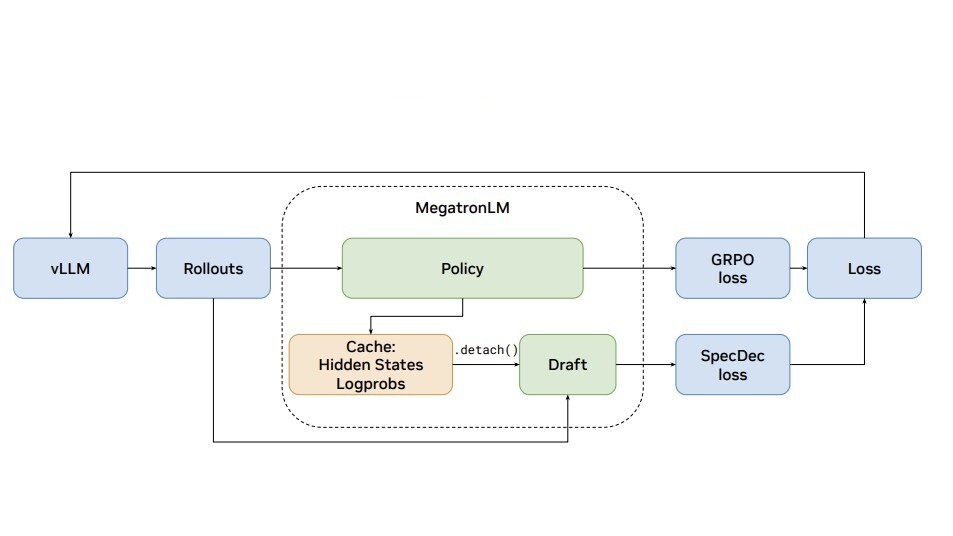
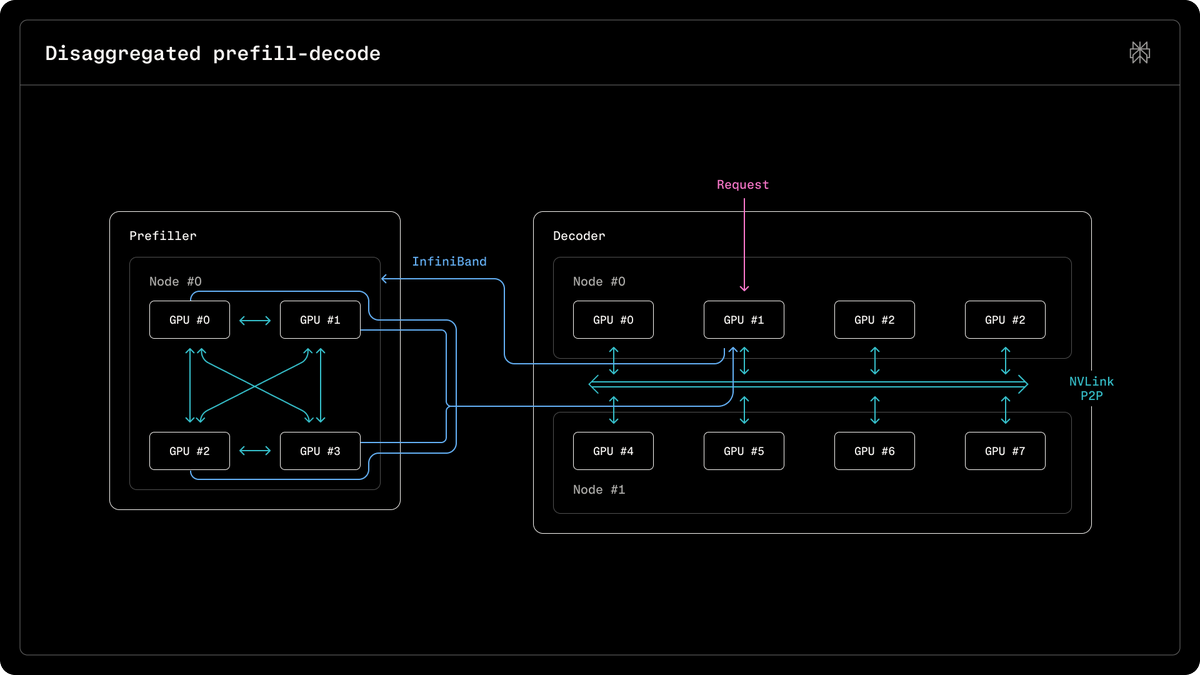
What if every decode step gave the next one a head start? Meet Guess-Verify-Refine — a new hardware-aware sparse-attention algorithm from NVIDIA Research. Built for TensorRT LLM on Blackwell, it reuses temporal patterns across decode steps for: → 1.88x faster Top-K attention → 9.3% better end-to-end latency in low-latency serving Dive into the paper: https://t.co/quu7wX9sCh
24retweets139likes
View on X