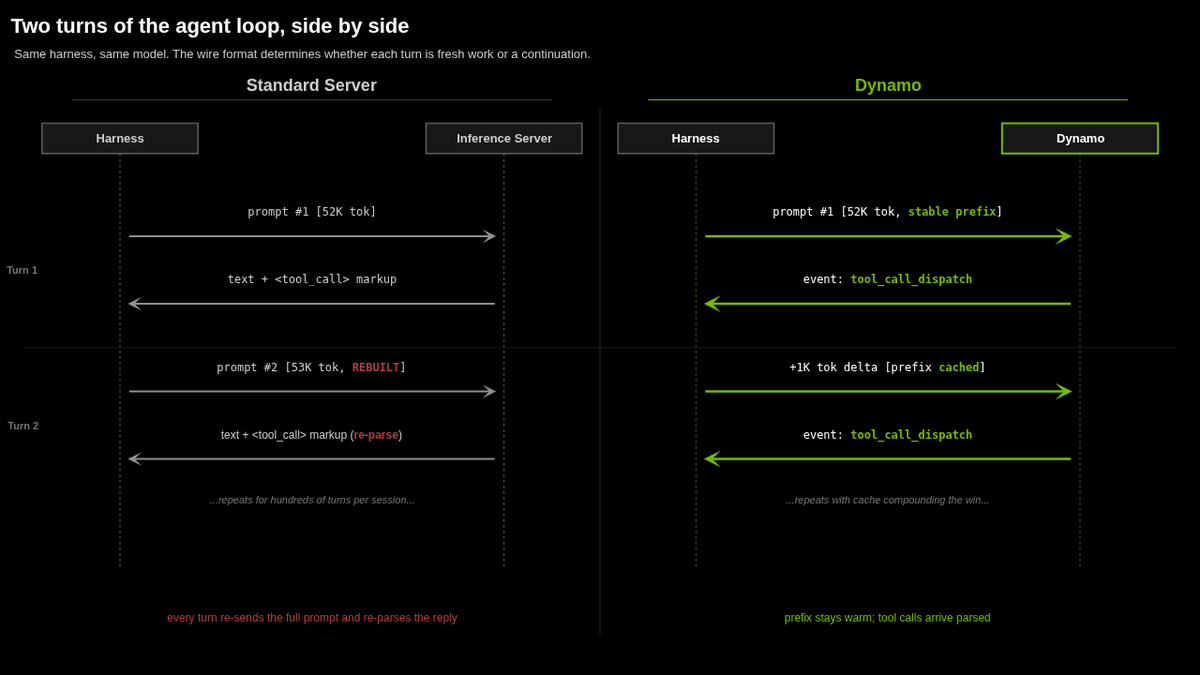
NVIDIA updated its Dynamo inference orchestrator with agent-native optimizations that deliver up to 7x more throughput for multi-step AI workflows. By introducing KV-aware routing and a four-tier memory hierarchy, the system eliminates redundant recomputations in long-running agent sessions.
NVIDIA updated Dynamo, its open-source inference orchestration layer, with optimizations for agentic AI (systems that plan and act autonomously). The update introduces agent_hints, an API for passing metadata like task priority to the stack, plus native support for protocols that handle interleaved thinking and tool calls.
- Throughput increase
- Up to 7x more
- Cache hit rate
- 85-97%
- Memory hierarchy tiers
- 4 (GPU, CPU, NVMe, Remote)
- Routing performance
- 170M ops/s
- Read to write ratio
- 11.7x
- Supported protocols
- v1/chat, v1/responses, v1/messages
Traditional inference was built for chat, but agents make hundreds of API calls with 97% context overlap. This "write-once-read-many" pattern overwhelms standard caches. These optimizations follow NVIDIA Dynamo 1.0 to give self-hosted models the same cache-reuse efficiency found in frontier APIs.
You can now use the Dynamo router for KV-aware placement (routing based on stored model memory), sending requests to the GPU worker holding the relevant context. The system uses a four-tier memory hierarchy to pin system prompts while evicting ephemeral reasoning tokens. The agent_hints API is available on GitHub.