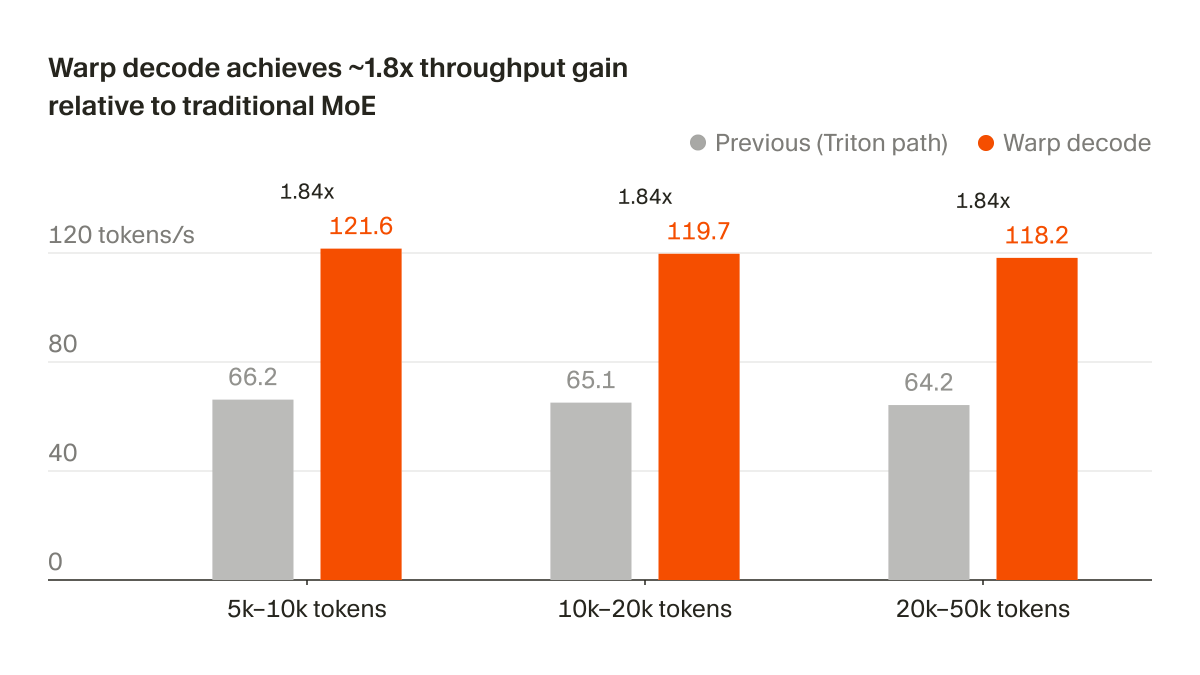
Cohere released production-ready W4A8 quantization kernels for dense and Mixture of Experts models, now integrated into the vLLM inference framework. By combining 4-bit weights with 8-bit activations, the update achieves up to 58 percent faster prefill and 45 percent faster decoding on NVIDIA Hopper GPUs.
Cohere, an AI company building enterprise models for search and business applications, integrated W4A8 inference (a mixed-precision scheme using 4-bit weights and 8-bit activations) into the vLLM framework. This update targets NVIDIA Hopper architecture, optimizing for FP8 Tensor Cores to accelerate both prefill and decoding phases.
- TTFT speedup
- Up to 58%
- TPOT speedup
- 45%
- Weight precision
- 4-bit INT4
- Activation precision
- 8-bit FP8
- Calibration context
- Up to 64K tokens
- Target architecture
- NVIDIA Hopper
Standard 4-bit quantization often relies on 16-bit activations, saving memory but missing the fastest compute engines on modern GPUs. This release mirrors the industry shift toward specialized quantization by bridging that gap. A lookup-table approach dequantizes weights without the scalar math overhead that typically bottlenecks FP8 kernels.
Deploy Command A or Mixture of Experts models with lower latency for long-context agentic workflows. This work extends recent research on MoE efficiency and includes a new token masking feature in the llm-compressor library. These kernels are available now via the official vLLM repository for production use.