Cohere
@cohere
Get more from speculative decoding in MoE models https://t.co/JHVcCUAmZT
7retweets34likes
View on X· Updated
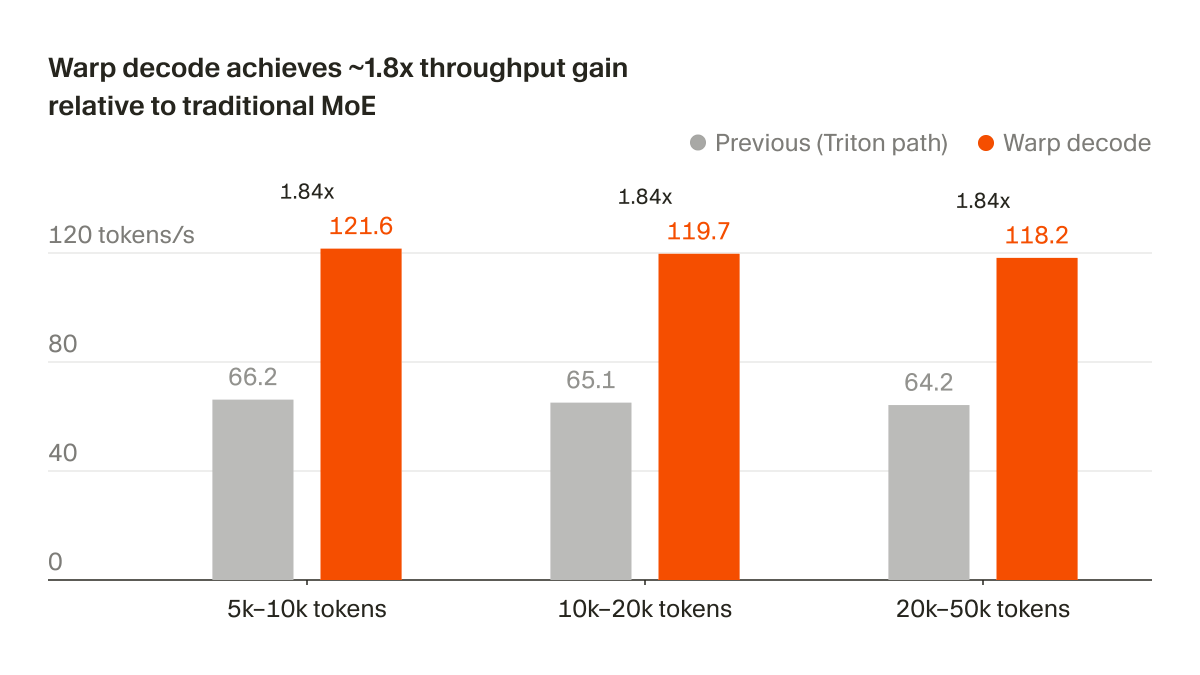
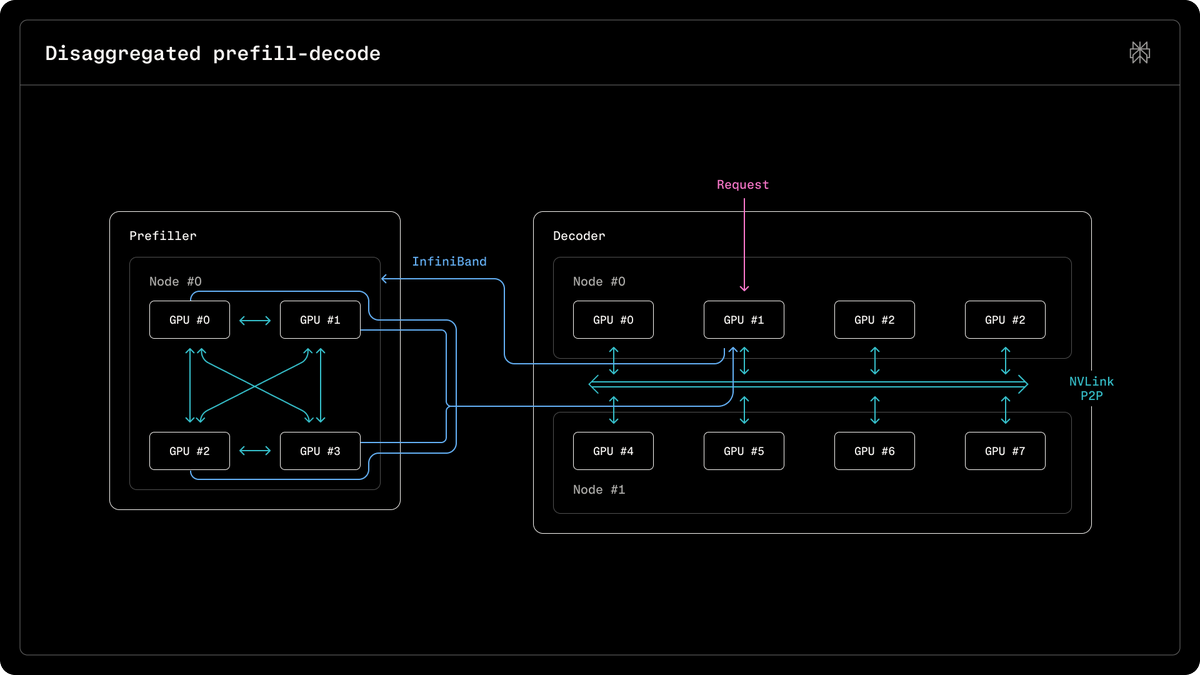
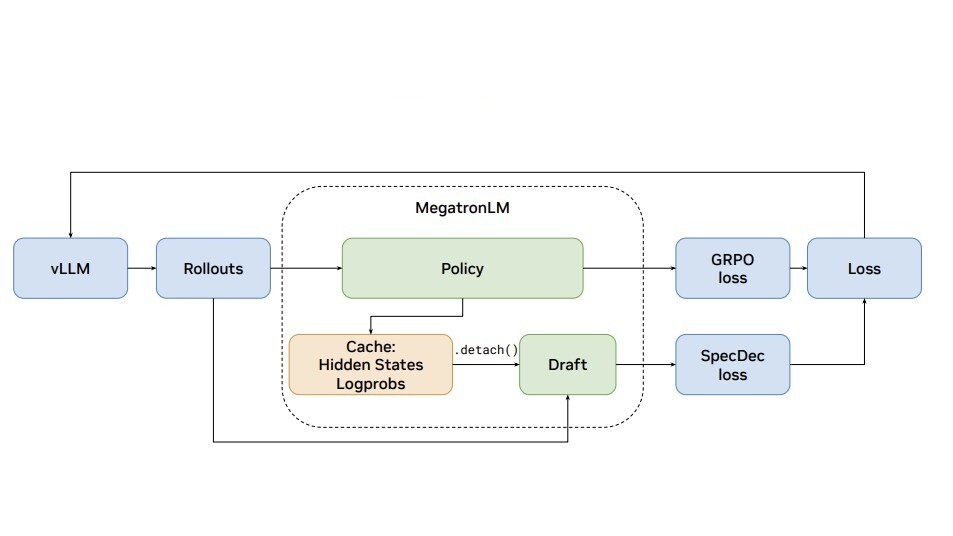
Cohere validated that Mixture-of-Experts models achieve higher speedups from speculative decoding than dense models by staying in a memory-bandwidth-bound sweet spot. The research shows that consecutive tokens naturally reuse the same experts, significantly reducing the data-loading bottleneck during parallel verification.
This challenges the assumption that loading multiple experts during verification would erase speed gains. It mirrors the pattern seen in optimized inference paths for Blackwell GPUs, where reducing data-shuffling overhead is critical. Cohere proved that temporal correlation between adjacent tokens reduces unique weight loading by up to 31%.
You can apply these insights by co-optimizing model sparsity and batch sizes to stay in the bandwidth-bound regime. For high-volume workloads, lowering the active expert ratio preserves these speedups at scale. These findings follow the release of optimized W4A8 quantization kernels for the vLLM engine and Command models.
Get more from speculative decoding in MoE models https://t.co/JHVcCUAmZT
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this