Together AI
@togethercompute
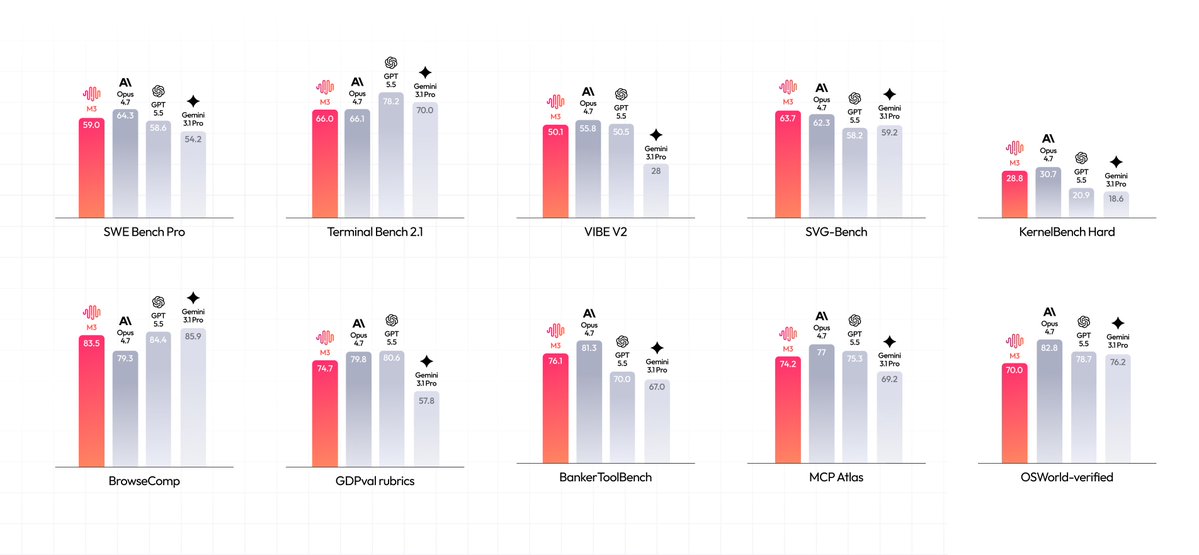
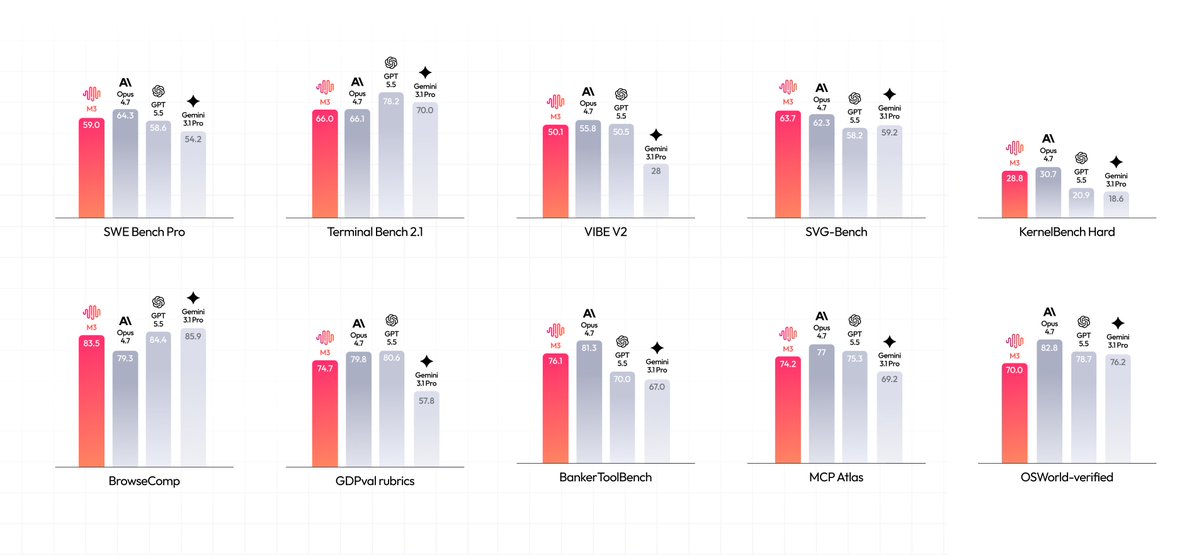
M3’s architecture makes long-context inference more efficient. Serving it at production scale required systems work. Together’s kernel and inference teams built KV-block-major sparse attention, integrated MSA with paged KV cache, optimized decode index scoring, and moved multimodal preprocessing into a Rust gateway before requests reach GPU workers.
3retweets40likes
View on X