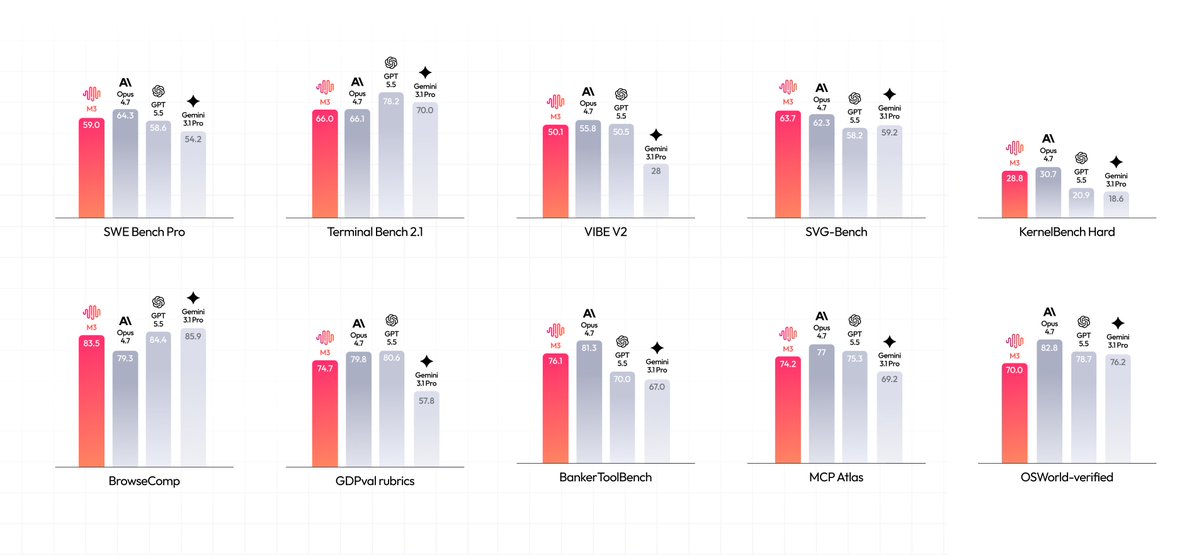
- Decoding Speedup
- 15.6x at 1M tokens
- Architecture
- MiniMax Sparse Attention (MSA)
- Context Window
- 1,000,000 tokens
- Inputs
- Interleaved text, image, video
- Availability
- Fireworks AI (weights to community on release)
MSA lets the model scale to a 1-million-token context without the exponential computational cost of standard attention, removing the usual speed penalty on long-context work. The model accepts interleaved text, image, and video inputs, supporting multimodal workflows beyond plain text generation.
You can now access MiniMax M3 through Fireworks AI for applications requiring massive context. While the model weights are currently restricted, M3 will be available to the Fireworks community once they are released, following rollouts on inference providers like SiliconFlow.