MiniMax (official)
@MiniMax_AI
Day-0 on SiliconFlow and 50% off 🔥 the first week frontier coding, 1M context, and native multimodal, all in one open-weights model. This is what we built M3 for. Go try it 👇
1retweets66likes
View on X· Updated
MiniMax M3 is now available on SiliconFlow, bringing frontier-grade agentic coding and a million-token context window to the open-weight ecosystem. The launch includes a week-long introductory discount, making high-capacity multimodal reasoning significantly more accessible for developers.
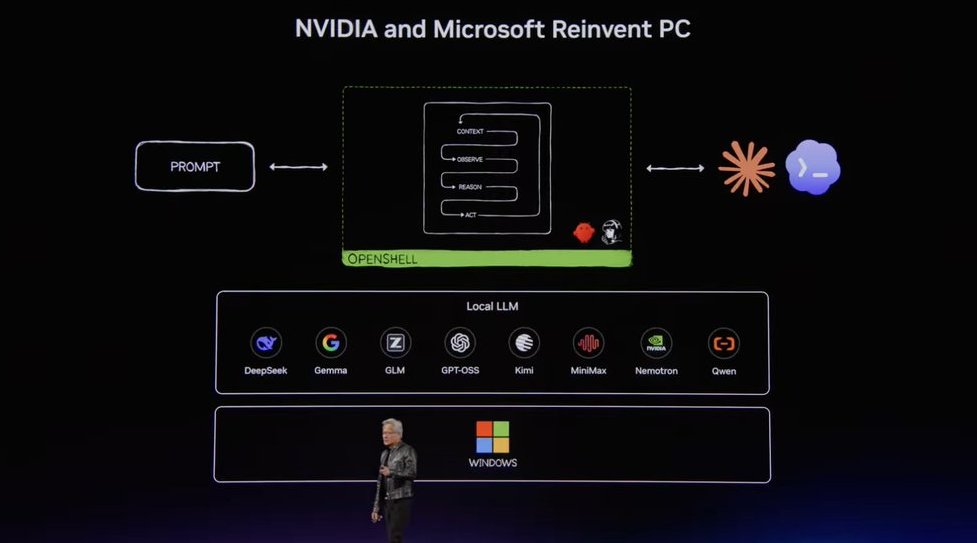
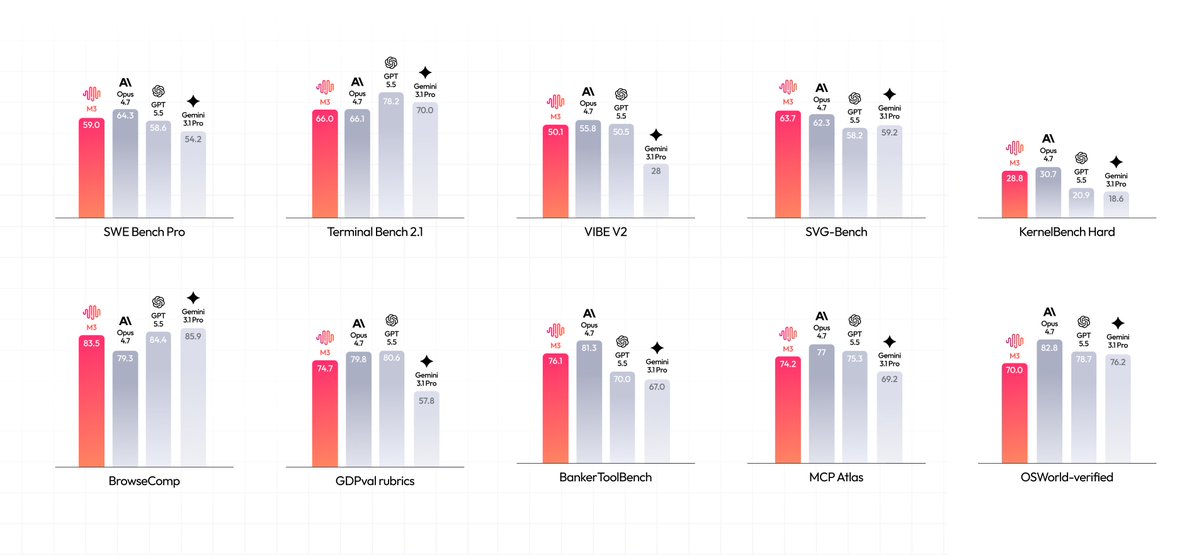
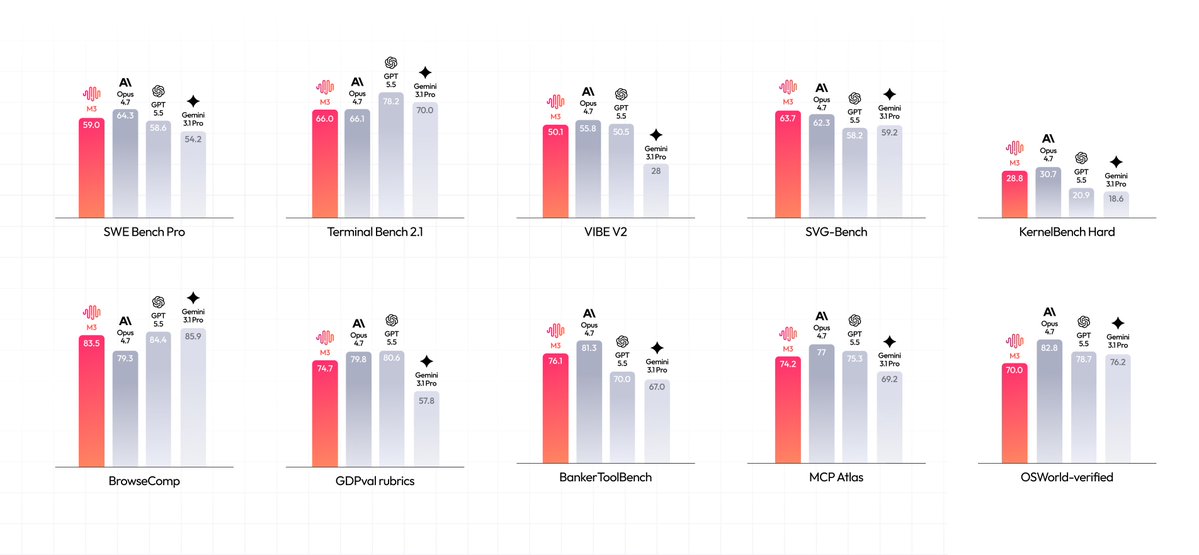
This release challenges closed systems by matching performance on specialized benchmarks. MiniMax-M3 scores 83.5 on BrowseComp, surpassing Opus 4.7, and outperforms GPT-5.5 on software engineering tasks. Its MSA architecture enables 9.7x faster prefilling and 15.6x faster decoding at full context, reducing the compute required for long-horizon reasoning.
Developers can access the model via SiliconFlow's API, with a 50% discount through June 7th reducing rates to $0.30 per 1M input tokens. Like the model being available on OpenRouter and brought to Together AI, this launch enables autonomous codebase analysis through tools like Claude Code and Cline.
Day-0 on SiliconFlow and 50% off 🔥 the first week frontier coding, 1M context, and native multimodal, all in one open-weights model. This is what we built M3 for. Go try it 👇
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this