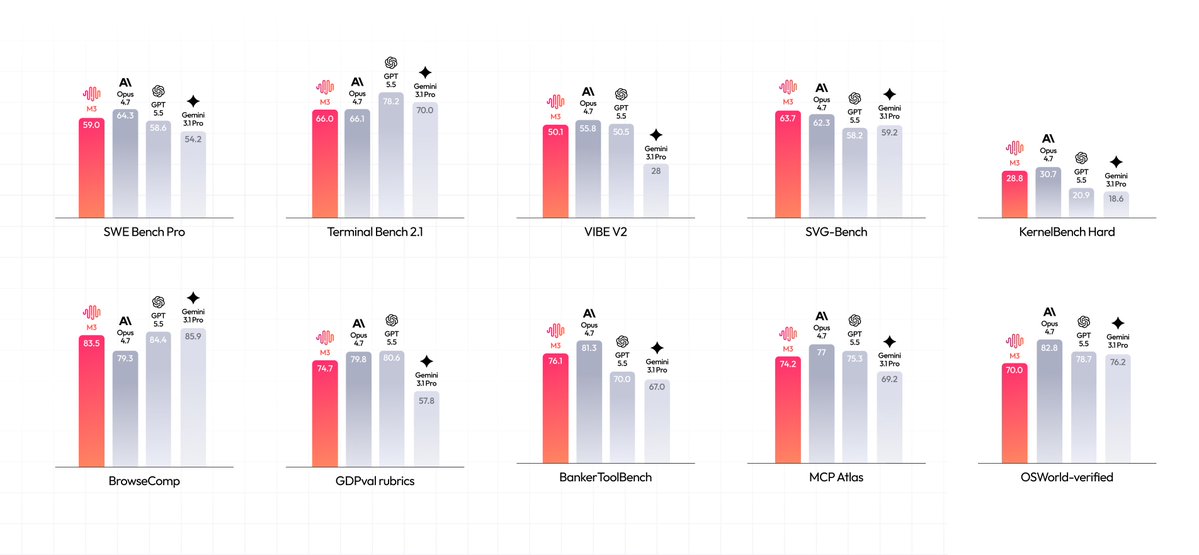
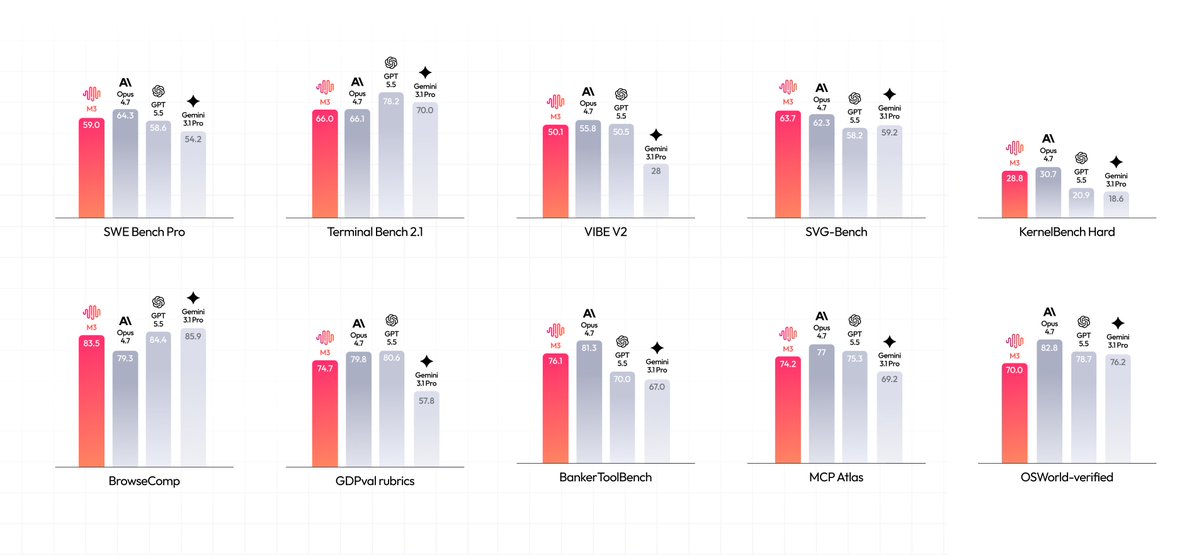
Together AI is now powering inference for MiniMax M3, a multimodal model featuring a 1-million-token context window. The model uses a new sparse attention architecture to process massive datasets with significantly lower computational overhead than previous-generation models.
Together AI, a research-optimized platform for model inference, is now hosting inference (running a trained model to generate outputs) for MiniMax M3, a multimodal model with a 1-million-token context window. It uses MiniMax Sparse Attention (MSA) to process massive datasets without the exponential compute costs of full attention.
- Context Window
- 1,000,000 tokens
- Architecture
- MiniMax Sparse Attention
- Coding Benchmark
- 59.0% SWE-Bench Pro
- Agent Benchmark
- 74.2% MCP Atlas
- Input Modalities
- Text, Image, Video
MiniMax M3 matches full attention performance across multiple benchmarks while reducing per-token compute to 1/20th of previous generations at a 1-million-token context length. This architecture enables autonomous workflows like CUDA kernel optimization, building on the MiniMax M3 technical highlights. The model's native multimodality allows semantic spaces to merge deeply during training.
Access MiniMax M3 via the MiniMax Code app or the Together AI API, available alongside other providers like SiliconFlow. The model supports "thinking" modes for reasoning and "computer use" for desktop automation. Together AI provides the research-optimized infrastructure required to deploy and scale these models in production.