We wrapped a live session on M3 yesterday with the @togethercompute team & our researchers @zpysky1125 and @HaohaiSun A few highlights 🧵 1. MSA (MiniMax Sparse Attention) is the star ⭐️. Unlike CSA/HCA, which compress the KV cache, MSA keeps the real, uncompressed KV and does block-level selection with a small top-K. That's how the 1M context window stays tractable. 2. The efficiency win is huge. In our previous generation, ~30% of per-decode wall-clock time went to the attention kernel. With MSA that now drops to ~5%. Big gains for long-context generation. 3. M3 isn't just a coding model. Natively multimodal (image + video in), ability to handle long-horizon agentic tasks, and even operate a desktop computer. People are already throwing game-dev + Minecraft-style builds at it (Unity included) and it's holding its own. 4. M3 can self-evaluate on vision-coding tasks: it builds a website or SVG, browses and inspects its own rendered output, judges it, and iterates - grading work visually. 5. We're also seeing junior-analyst-level performance on finance tasks; something we haven't even showcased publicly yet. 6. What's next: harder long-horizon / multi-file tasks in future releases, scaling data + post-training (RL) compute toward pre-training scale, and going deeper into finance, legal & bio. Thanks to everyone who joined 🙏 Try M3 link in the comments👇
MiniMax M3 drops attention overhead from 30 to 5 percent
· Updated
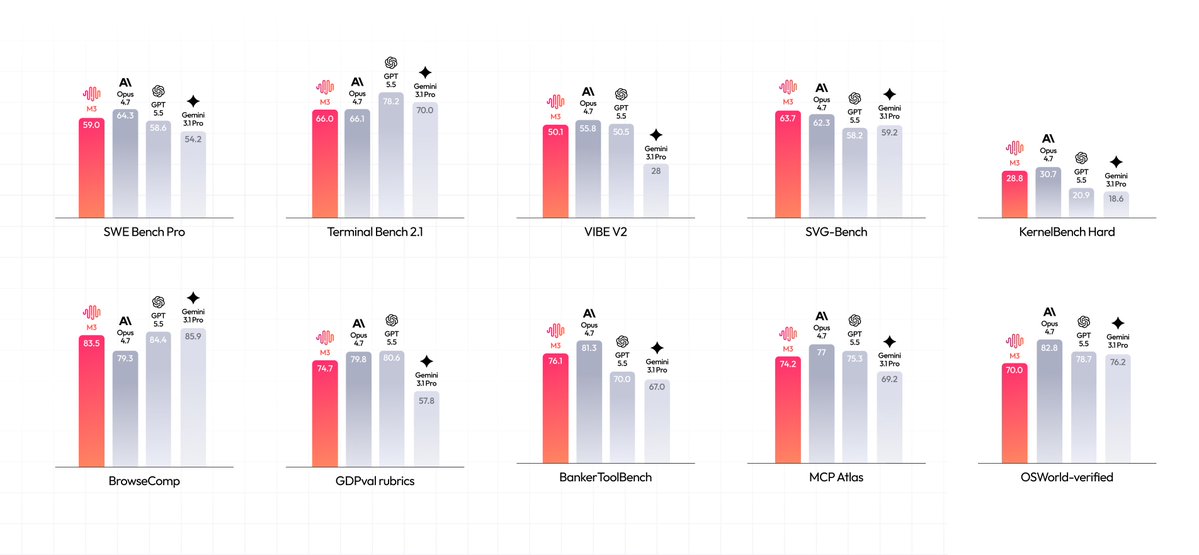
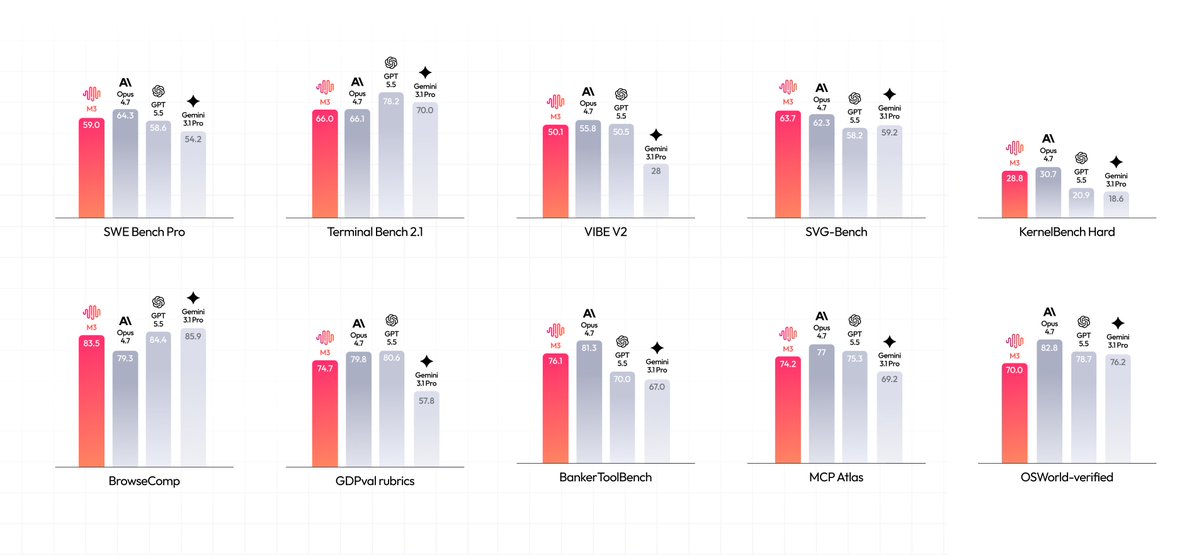
MiniMax revealed technical highlights for its M3 model, featuring a Sparse Attention architecture that maintains uncompressed data for its 1-million-token context window. The update reduces attention kernel overhead from 30% to 5% of per-decode wall-clock time and introduces vision-coding capabilities where the model self-evaluates its own rendered UI.
- Context Window
- 1,000,000 tokens
- Attention Kernel Time
- 5% of per-decode wall-clock time
- Input Modalities
- Text, Image, Video
- Architecture
- MiniMax Sparse Attention
At full context, the attention kernel consumed 30% of per-decode wall-clock time; MiniMax Sparse Attention drops that to 5%. MiniMax-M3 is natively multimodal, accepting image and video inputs, and can operate a desktop computer. It also performs vision-coding tasks by rendering its own output, inspecting the results, and iterating based on its own judgment.
Beyond coding, the model demonstrates junior-analyst-level performance on finance tasks and handles long-horizon agentic workflows. Future releases will focus on multi-file tasks and scaling post-training compute. The model is available via the MiniMax platform, and is also offered through inference providers including SiliconFlow and Together AI.
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →