- Model
- MiniMax-M3 (open-weight)
- Lineup
- NVIDIA + Microsoft Local LLM (GTC Taipei)
- Lineup Peers
- DeepSeek, Gemma, Qwen, GLM, and others
- Windows Architecture
- OpenShell agentic stack
- Context Window
- 1M server-class, reduced on consumer
- Weights Release
- Ships in under 10 days
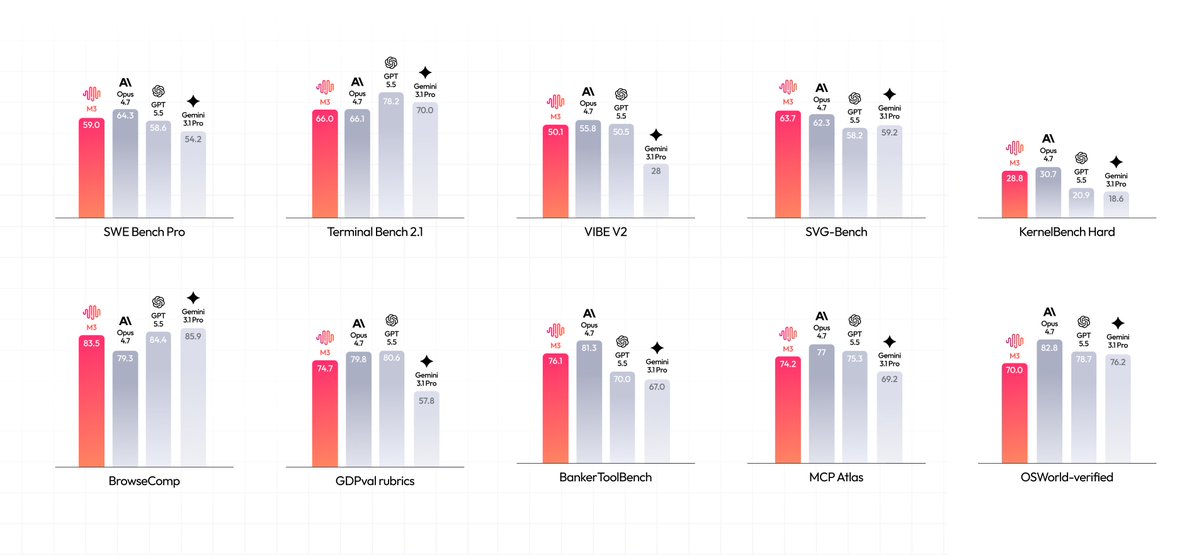
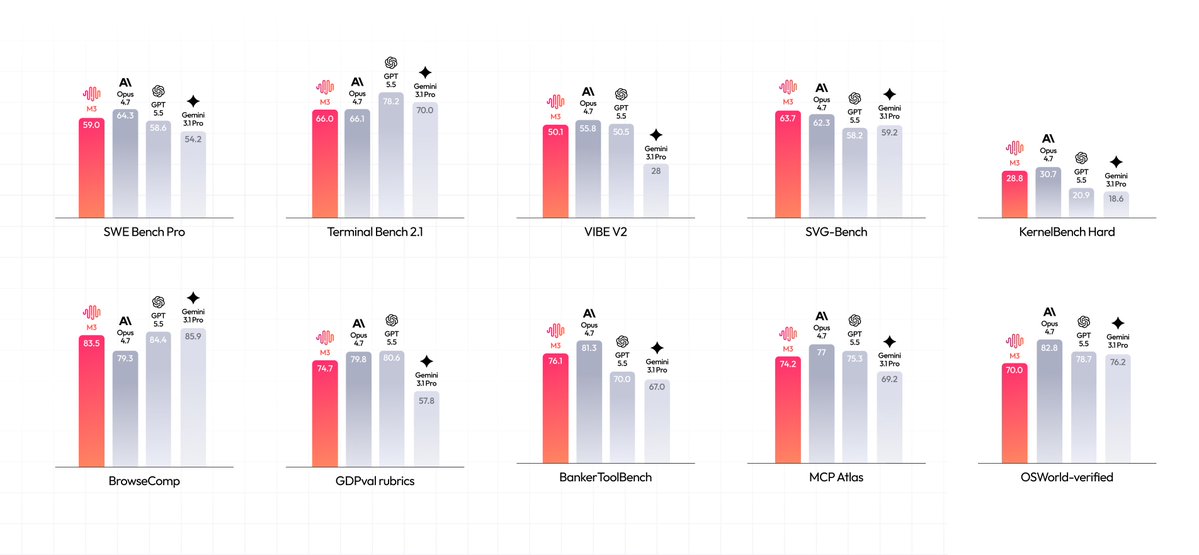
This release bridges the gap between cloud capacity and local privacy. By utilizing MiniMax Sparse Attention, the model reduces overhead to maintain performance. It holds strong benchmarks in agentic coding, offering a local alternative for developers who need to process entire codebases or long video files on-device.
Consumer PCs will require quantization (compressing models to run on smaller chips) and reduced context, but full weights will be available for self-hosting in under 10 days. This enables workflows where sensitive data stays local while still benefiting from frontier-level reasoning and native multimodal support.