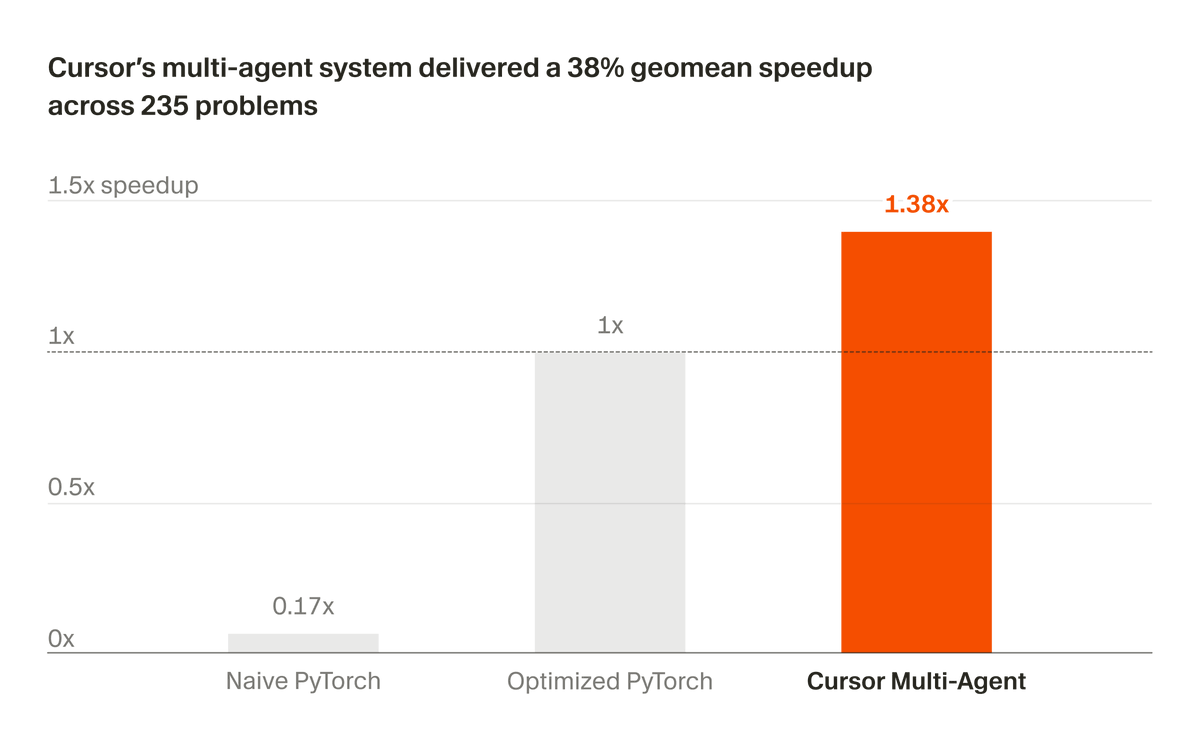
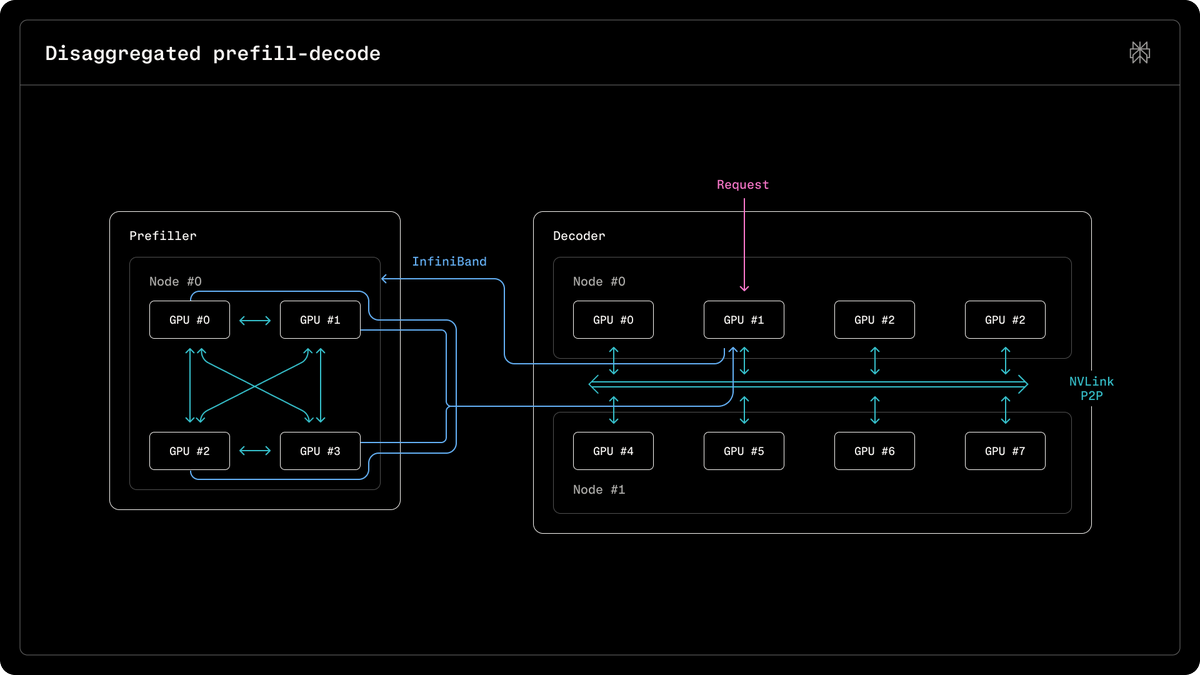
Anysphere rebuilt the Mixture of Experts inference path for NVIDIA Blackwell GPUs, achieving 1.84x faster throughput by assigning GPU warps to individual output neurons. This warp decode approach eliminates the data-shuffling overhead typical of expert-centric models while improving output accuracy by 1.4x.
Cursor, an AI-native code editor built by Anysphere, introduced warp decode to optimize Mixture of Experts (MoE) (a model architecture using specialized sub-networks) inference. Traditional implementations organize computation around experts, requiring five bookkeeping stages to shuffle data. Warp decode flips this axis, assigning each 32-thread GPU warp to a single output value.
Standard MoE paths struggle during single-token generation where overhead isn't amortized. By eliminating intermediate memory buffers and cross-warp synchronization, this method achieves 58% of the Blackwell B200's peak memory bandwidth. It also improves accuracy by keeping activations in BF16, avoiding the rounding errors found in common quantization methods.
These improvements accelerate the training pipeline for Composer, the model powering Cursor. While not a replacement for expert-centric prefilling, it allows the team to ship improved model versions more frequently. You will see these performance and accuracy gains reflected in the editor's responsiveness as the team scales its Blackwell infrastructure.