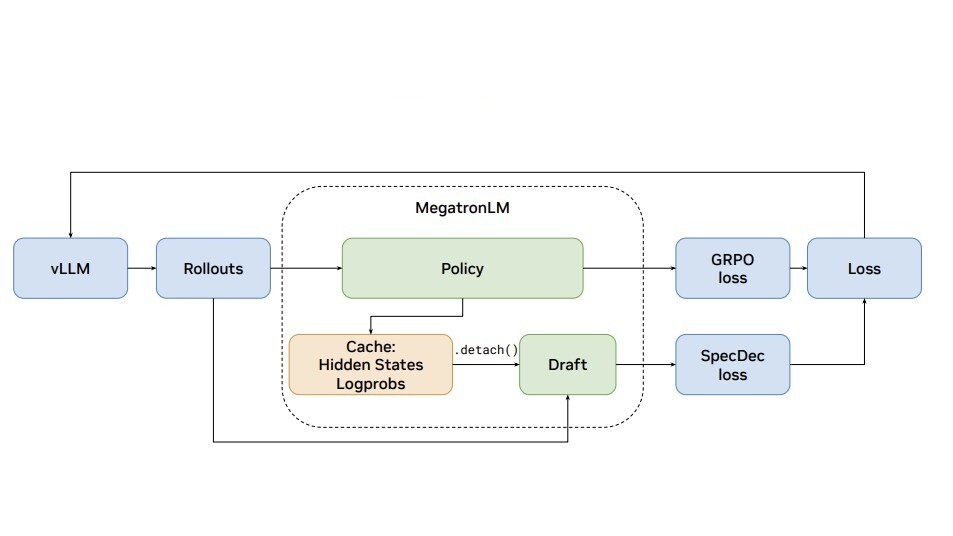
NVIDIA NeMo RL now supports end-to-end FP8 precision for reinforcement learning, enabling faster iterations for reasoning-grade models. By using importance sampling to maintain accuracy parity with high-precision training, the update delivers up to a 1.48x speedup on models like Qwen3. This shift makes the compute-intensive process of building agentic reasoning capabilities significantly more efficient for developers.
NVIDIA updated NeMo RL, an open-source library for model reinforcement learning, to support end-to-end FP8 precision. While low-precision math typically causes numerical errors during training, the new recipe uses importance sampling to match the accuracy of standard BF16 precision while delivering a 1.48x speedup on Qwen3 models.
- Speedup (Qwen3-8B-Base)
- 1.48x
- Throughput increase (Dense models)
- 15% to 25%
- Overall speedup (Linear + KV + Attention)
- ~48%
- Calibration overhead
- 2% to 3% of total step time
- Precision support
- End-to-end FP8 (E4M3)
- Supported models
- Llama 3.1, Qwen3, Moonlight
Building on NVIDIA's focus on inference-time compute, developers can now use FP8 to iterate faster on agentic tool use and multi-step workflows without the hardware overhead of high-precision training. This shift makes the compute-intensive process of building agentic reasoning capabilities significantly more efficient for teams training custom models.
You can now enable FP8 for linear layers, KV cache, and attention within the NVIDIA NeMo framework. The system handles dynamic recalibration, updating quantization scales at every training step to maintain stability. These recipes are available as open-source configurations on GitHub, supporting models like Llama 3.1 and Qwen3 on Blackwell and Hopper GPUs.