Most agentic stacks run into the same problems pretty quickly: reasoning and tool parsing drift across turns, KV cache reuse falls apart, or tools fire too late. We’ve been hardening Dynamo’s harness-facing path so @Claudeai Code, @OpenClaw, and @openai Codex-style agent patterns behave reliably on custom stacks and inference endpoints: • Stable prompts for KV reuse and lower TTFT • Interleaved reasoning + tool calls preserved across turns • Streaming tool dispatch instead of end-of-turn buffering • Harness behavior aligned with real multi-turn agent runtimes If you’re building your own agent stack or serving endpoint, this blog goes through the infrastructure issues that tend to show up in practice and the patterns we’ve been using to fix them. Tech blog ➡️https://t.co/dCWgk4OmyL
NVIDIA Hardens Dynamo to Match Frontier Agent Performance on Custom Stacks
· Updated
NVIDIA updated its Dynamo inference framework to support the specific multi-turn requirements of agent harnesses like Claude Code and Codex. The update eliminates infrastructure friction that causes reasoning drift and cache misses, allowing developers to run complex agents on private stacks with the same fidelity as managed frontier endpoints.
--strip-anthropic-preamble restore KV cache reuse, while streaming tool dispatch improves responsiveness. These changes follow the Dynamo agent-native inference stack launch.- TTFT reduction
- 5x (from 912ms to 169ms)
- Test prompt size
- 52K tokens
- Supported APIs
- Anthropic Messages, OpenAI Responses
- New flags
- --strip-anthropic-preamble, --enable-streaming-tool-dispatch
- Standalone crates
- dynamo-protocols, dynamo-parsers, dynamo-tokenizers
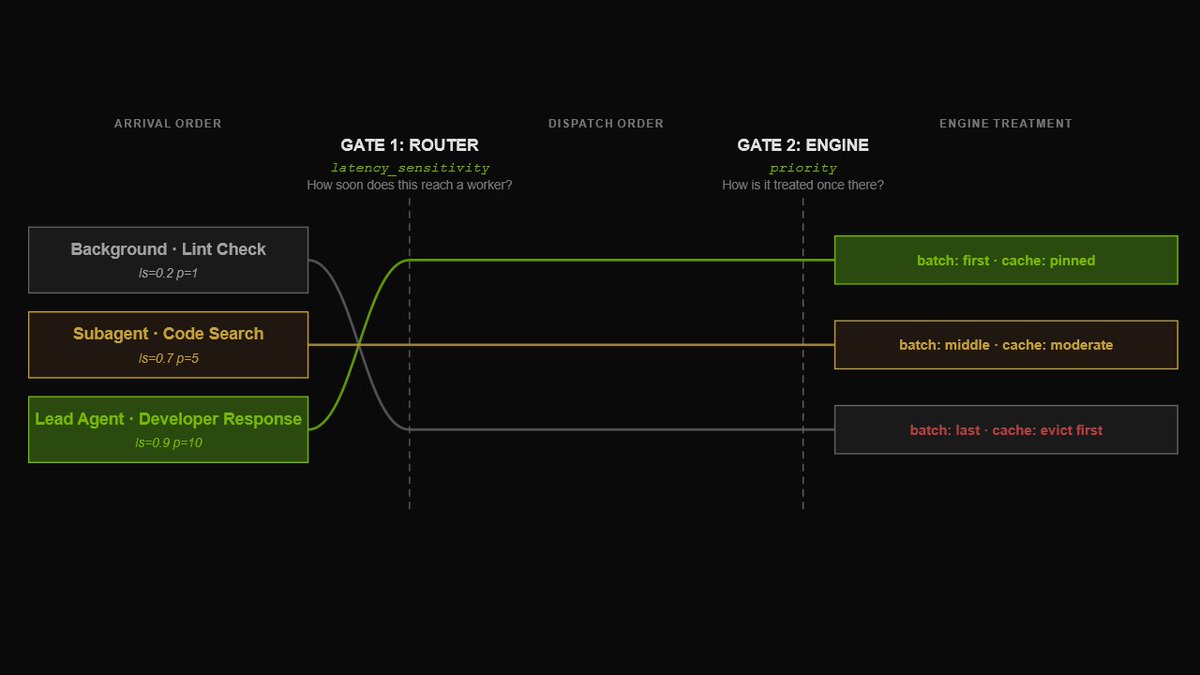
Standard inference servers often fail in agentic loops by buffering tool calls or dropping reasoning tokens. This creates a wait-to-act bottleneck and causes agents to lose their train of thought. By preserving interleaved reasoning, Dynamo ensures custom deployments maintain the same behavioral correctness as native frontier APIs.
You can now use Dynamo to serve models like Nemotron 3 Super for Claude Code or OpenClaw. For OpenAI Codex users, model-catalog aliasing prevents harnesses from falling back to low-performance profiles. Protocol and parser layers are also available as standalone crates like dynamo-parsers.
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →