Anthropic
@AnthropicAI
New on the Anthropic Engineering Blog: How we use a multi-agent harness to push Claude further in frontend design and long-running autonomous software engineering. Read more: https://t.co/HWvmXk1ykn
292retweets
View on X· Updated
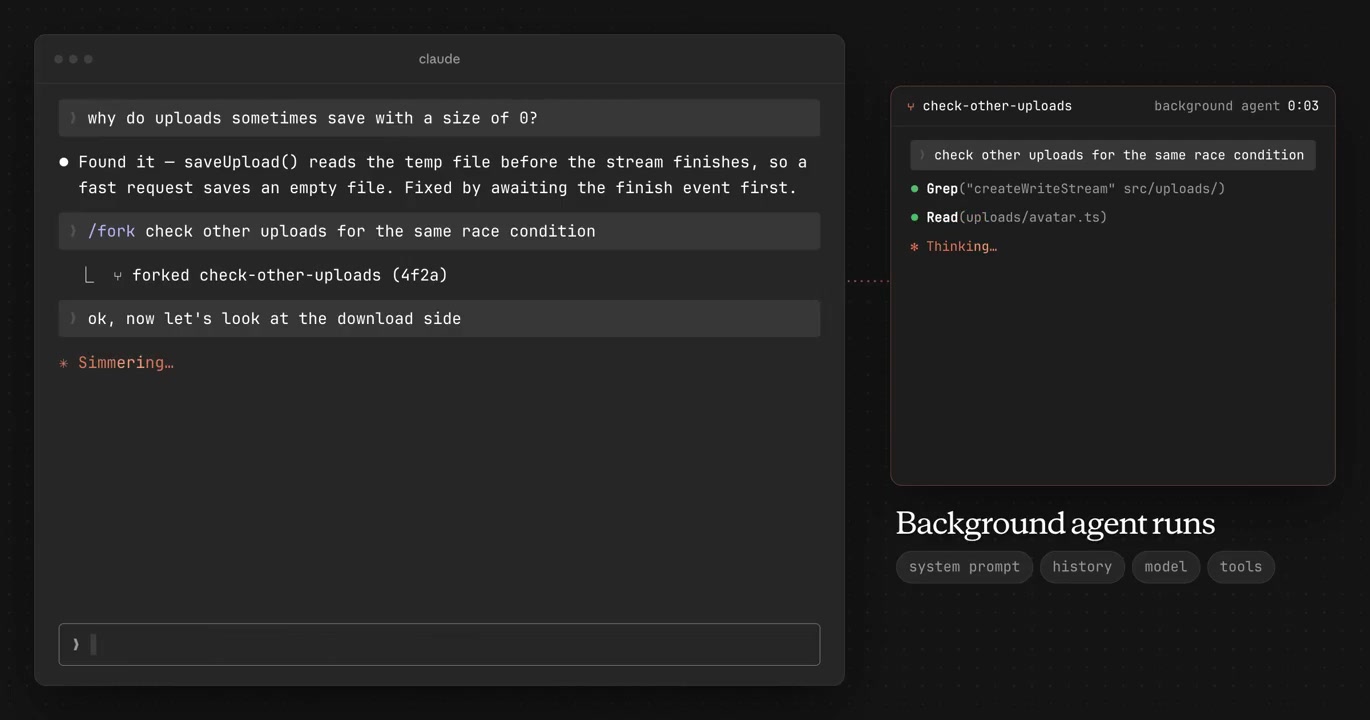
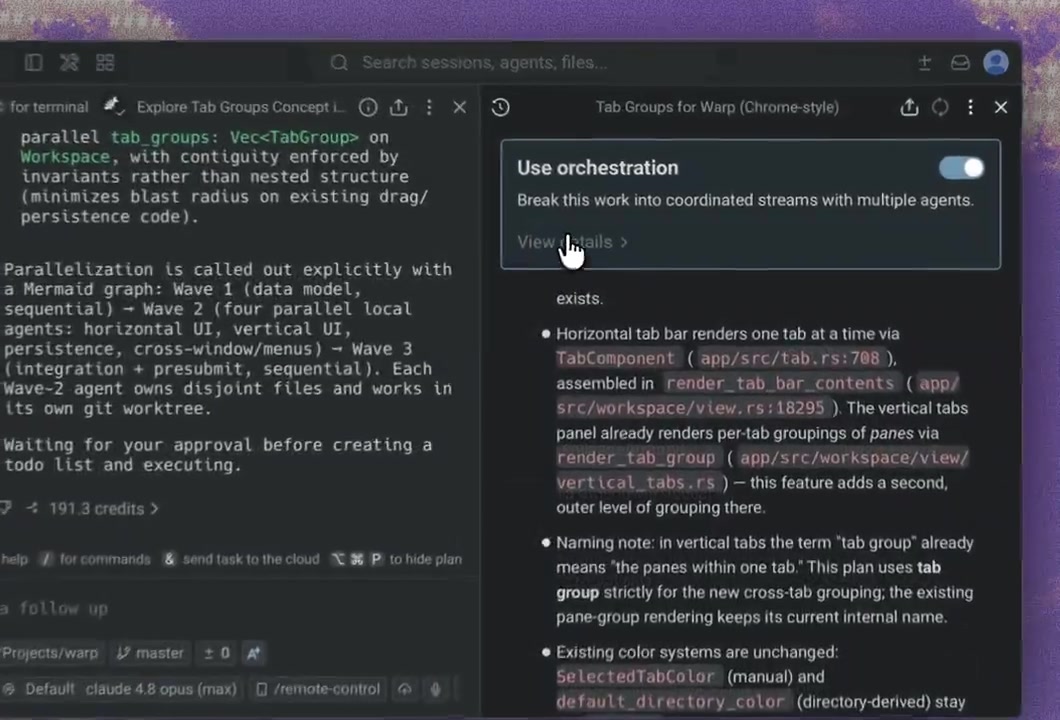
Anthropic's engineering team published a deep-dive on using a multi-agent harness to push Claude past single-agent ceilings on frontend design and full-stack development. A GAN-inspired generator-evaluator loop separates doing from judging — producing richer outputs than solo runs.
Agents reliably praise their own work — a tuned, skeptical evaluator gives the generator concrete feedback to iterate against, which is more tractable than self-critique. With Claude Opus 4.6, stronger long-context performance let the team drop sprint constructs and session resets the earlier harness required.
Apply the generator-evaluator pattern to your own agent harness for tasks where quality is subjective or hard to verify in one pass. The post includes sprint contract examples and evaluator tuning notes.
New on the Anthropic Engineering Blog: How we use a multi-agent harness to push Claude further in frontend design and long-running autonomous software engineering. Read more: https://t.co/HWvmXk1ykn
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →