Cursor
@cursor_ai
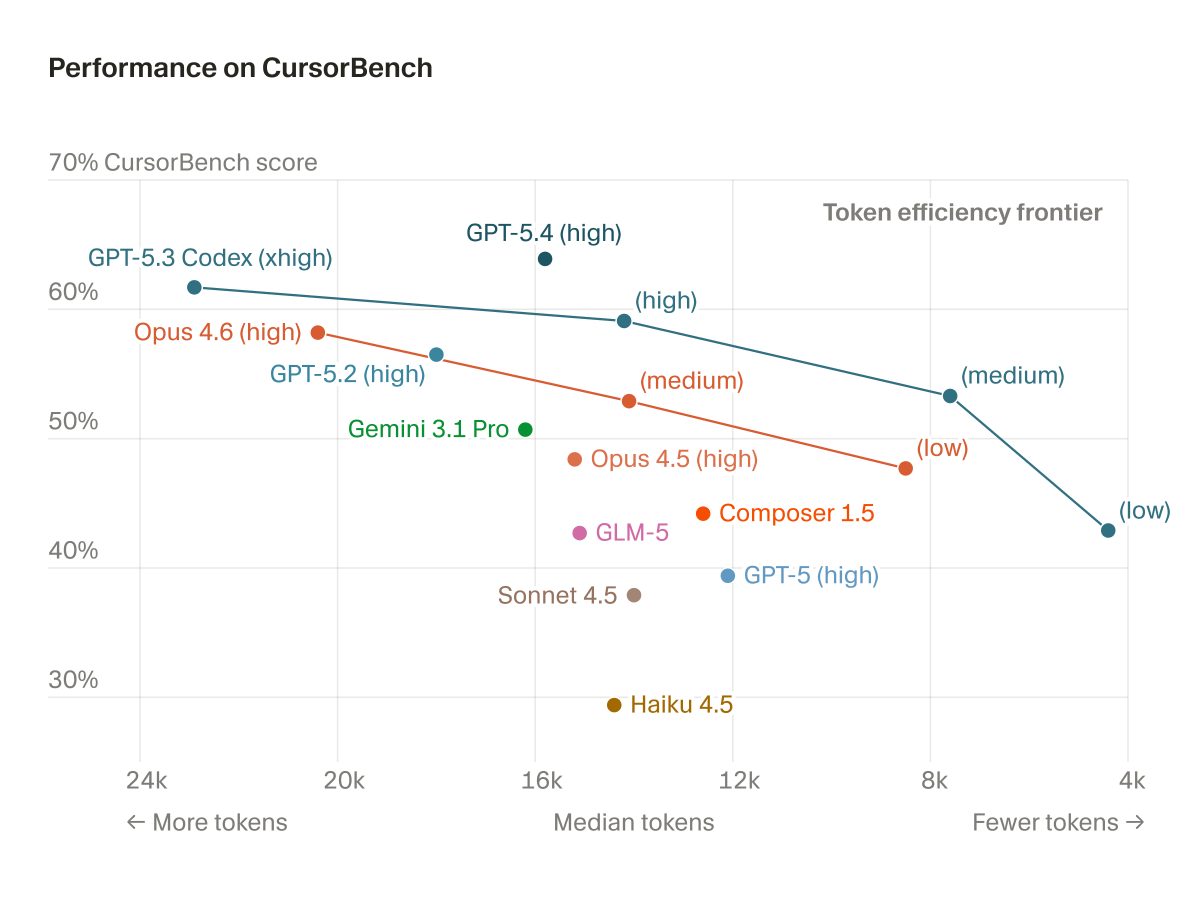
Our agent harness makes models inside Cursor faster, smarter, and more token-efficient. Here's how we test improvements to the harness, monitor and repair degradations, and customize it for different models. https://t.co/YIXcEZW6ud
49retweets609likes
View on X