Google AI Developers
@googleaidevs
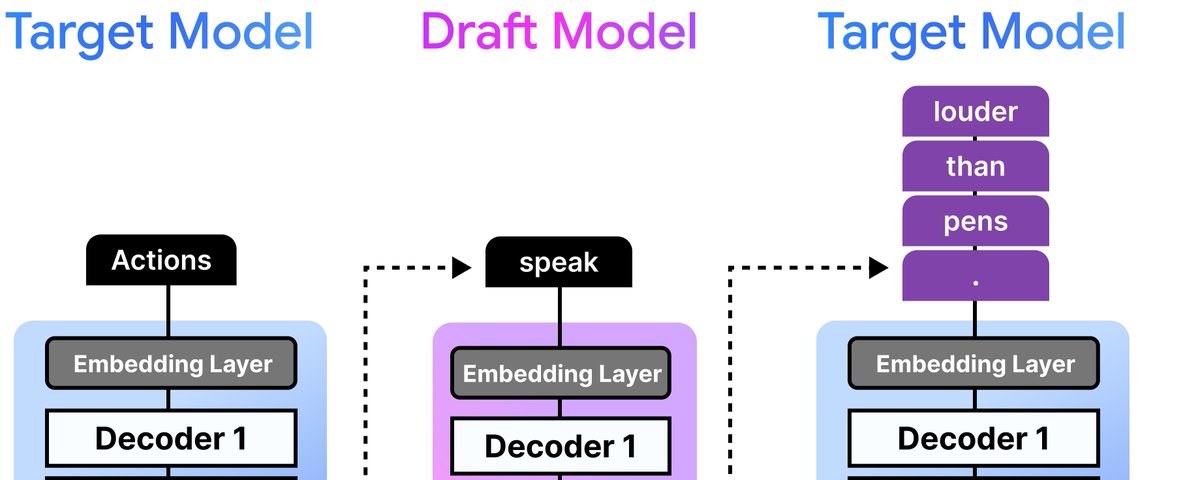
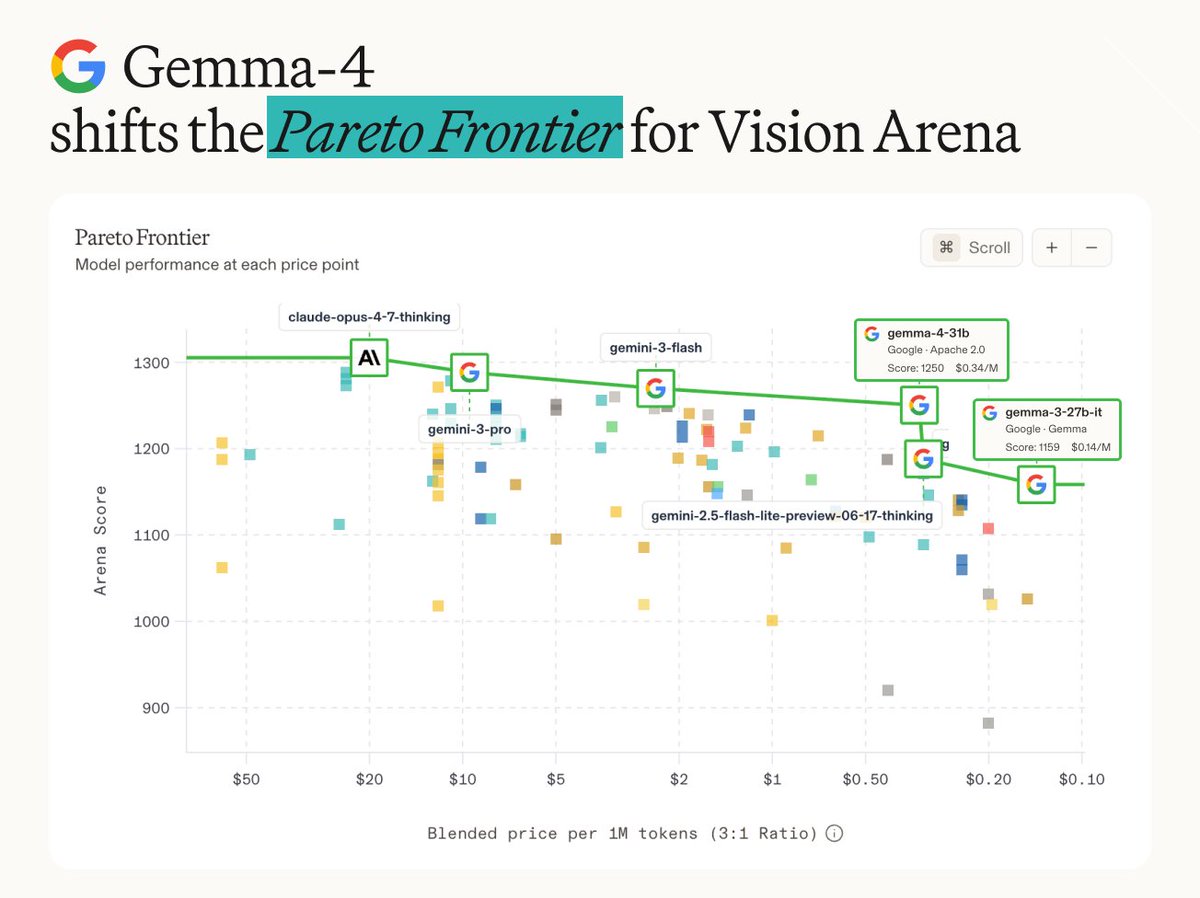
Zoom in on how @GoogleGemma 4 is optimized to handle high-concurrency serving for complex tasks (such as generating SVGs) — on a single GPU. ✓ 10+ sessions are sent to the 26B A4B model ✓ The system routes, accelerates, and processes those workloads — without bottlenecking ✓ A live dashboard visually tracks the load balancing in real time, displaying active slots, context sizes, and token generation speeds Watch the demo to see it in action ⬇️
14retweets151likes
View on X