Google Gemma
@googlegemma
https://t.co/BvHkG5TaBF
151retweets1klikes
View on XGoogle released a series of specialized drafter models that use speculative decoding to significantly increase the inference speed of the Gemma 4 family. By integrating architectural optimizations like shared activations and KV caches, these tiny models allow larger target models to verify multiple tokens in a single parallel pass.
This release addresses latency bottlenecks in Google's Gemma 4 models by moving beyond generic speculative decoding. These drafters recycle the target model's final activations and cross-attend to its existing KV cache. This architectural coupling maximizes speed gains without the memory overhead of maintaining separate state histories.
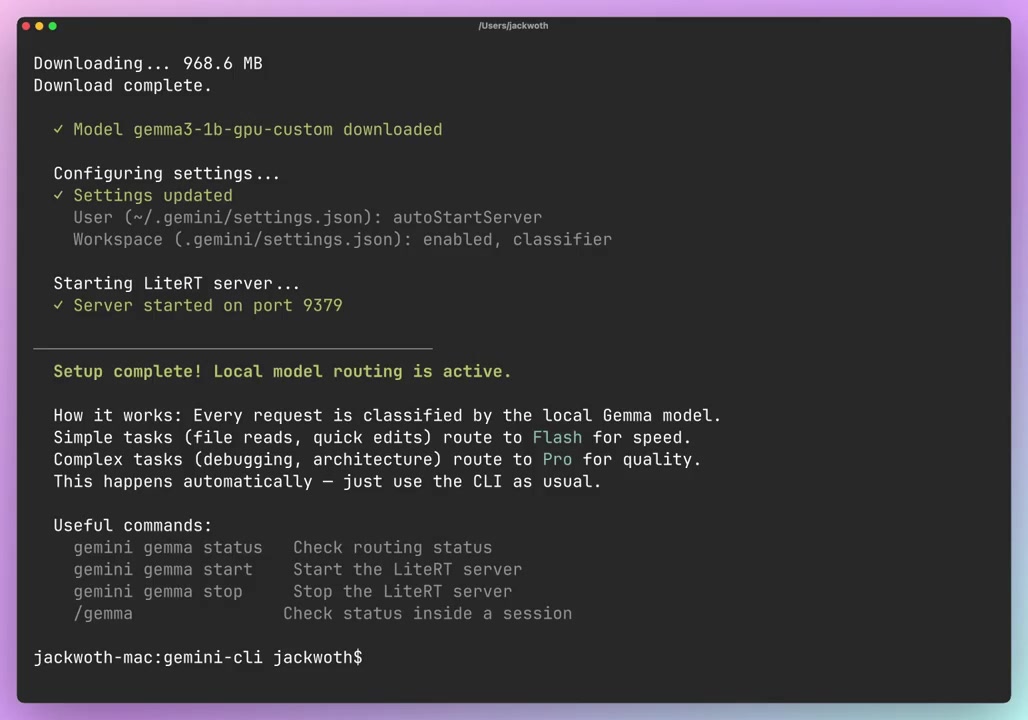
You can now deploy these drafter checkpoints for high-speed, low-latency generation in on-device applications. The release includes an "Efficient Embedder" for the E2B and E4B variants, which uses token clustering to reduce prediction compute. These open-weight checkpoints follow the Gemini CLI local integration roadmap for private local execution.
https://t.co/BvHkG5TaBF
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this