Perplexity
@perplexity_ai
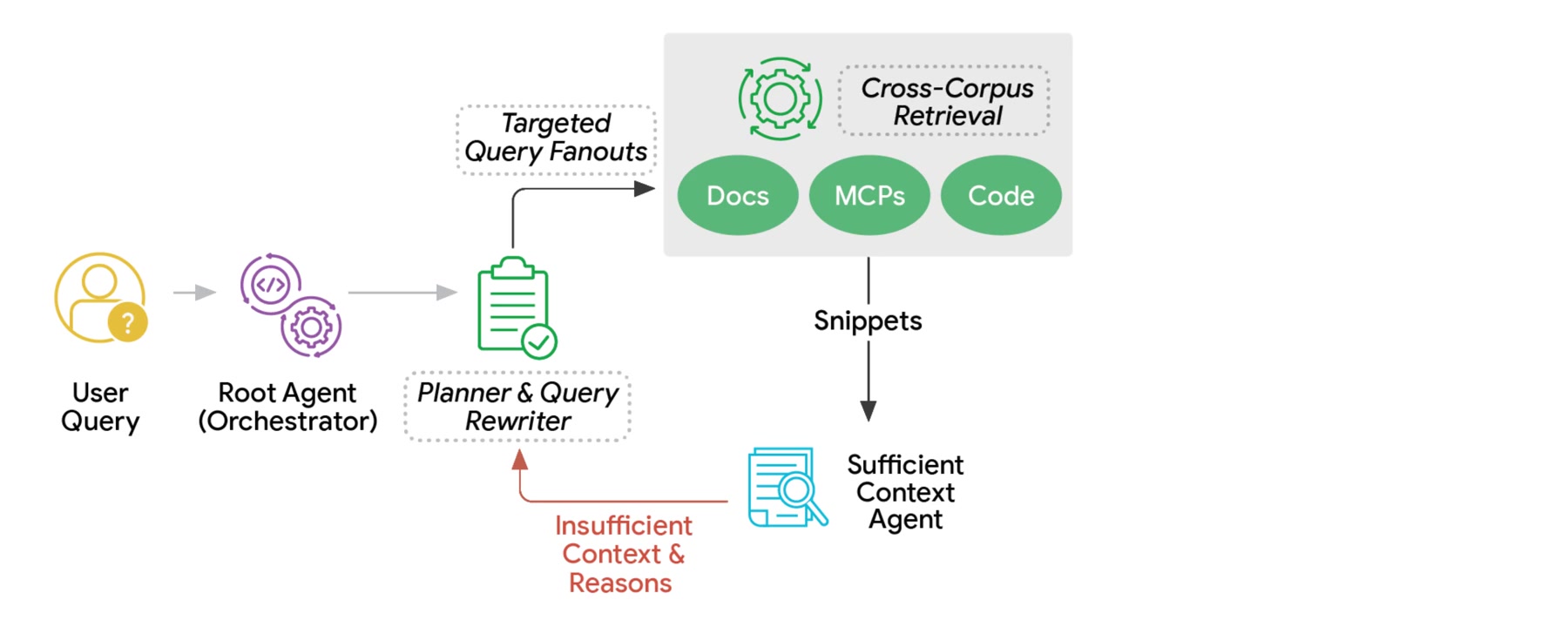
We've published new research on how we post-train models for accurate search-augmented answers. Our SFT + RL pipeline improves search, citation quality, instruction following, and efficiency. With Qwen models, we match or beat GPT models on factuality at a lower cost. https://t.co/0w0Jmc9xlS
141retweets1.7klikes
View on X