NVIDIA Dynamo 1.0 reaches production as open-source software that orchestrates GPU clusters for AI inference at data center scale. It boosts Blackwell GPU inference performance by up to 7x and already runs on AWS, Azure, Google Cloud, and OCI.
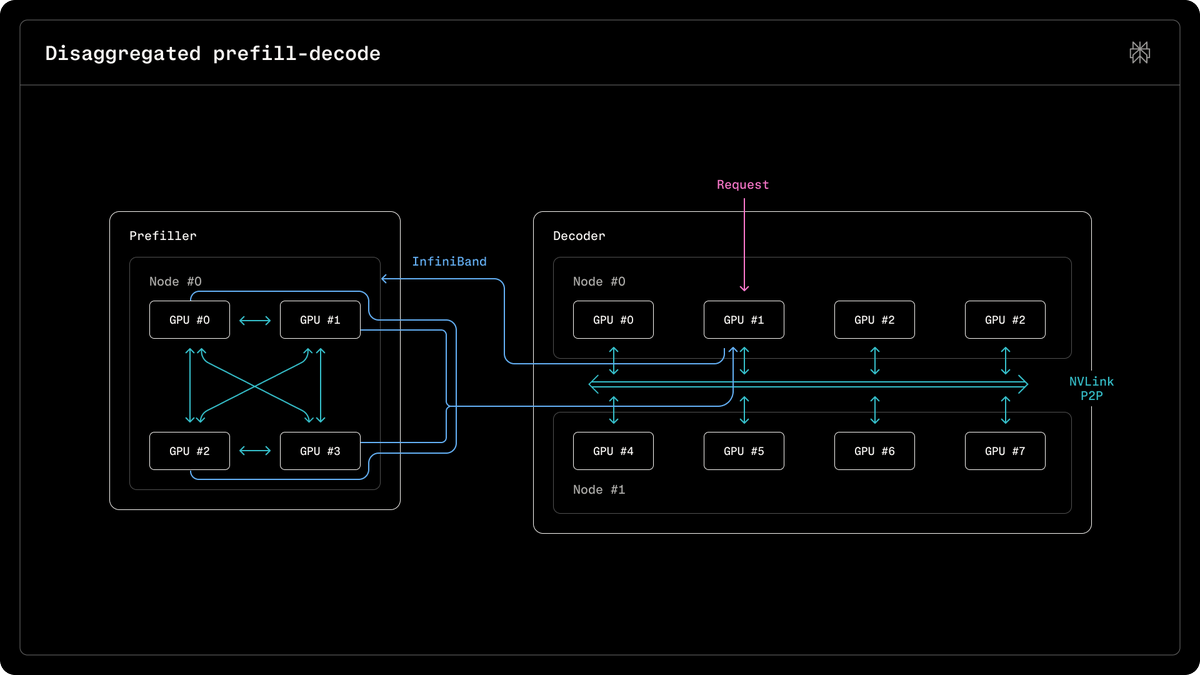
NVIDIA Dynamo 1.0 is a distributed inference orchestration layer that coordinates GPU and memory resources across an entire cluster. It routes requests to GPUs that already hold relevant cached context from earlier steps, offloads that context to lower-cost storage when idle, and splits workloads with smarter traffic control — reducing wasted compute and easing memory limits. On Blackwell GPUs, these optimizations deliver up to 7x inference performance gains.
Dynamo integrates natively into popular open-source inference frameworks including vLLM, SGLang, LMCache, and LangChain, with standalone modules like KVBM for memory management and NIXL for GPU-to-GPU data movement. Adoption spans all four major cloud providers, AI-native companies like Cursor and Perplexity, inference providers Baseten, Deep Infra, and Fireworks, and enterprises including ByteDance, PayPal, and Pinterest.
Drop Dynamo's KVBM module into your existing vLLM setup to handle KV cache management independently — a low-risk way to test distributed memory optimization without touching your inference stack.