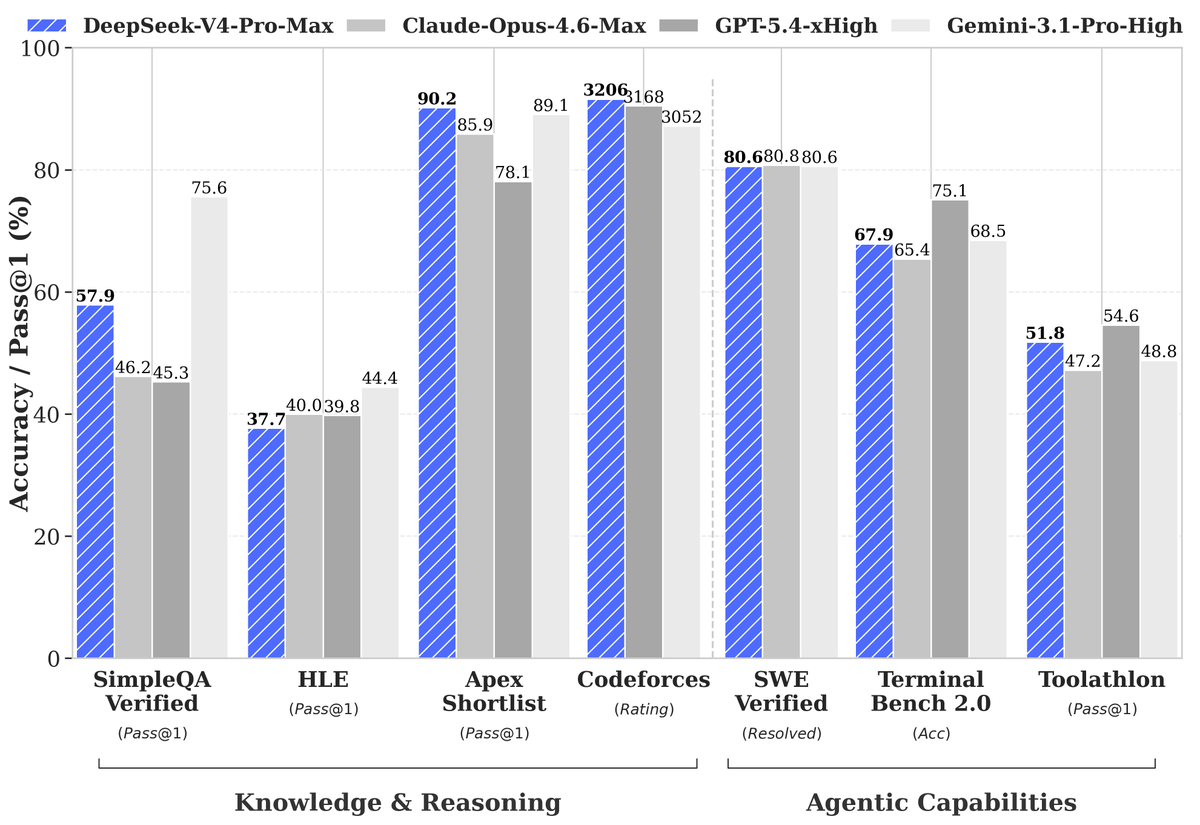
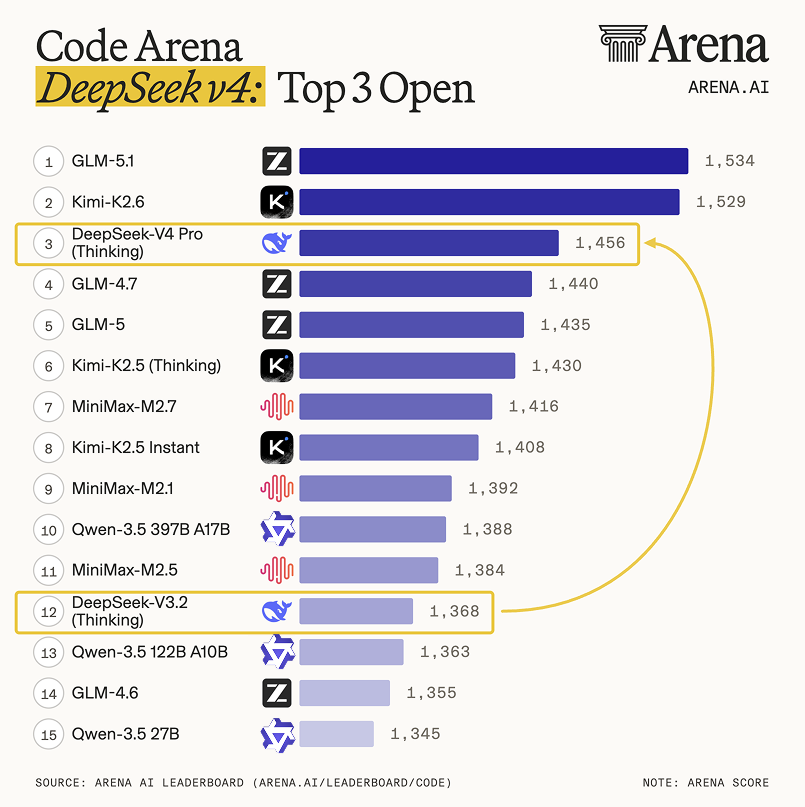
DeepSeek released the preview and open weights for DeepSeek-V4, a Mixture-of-Experts model family with a 1.6-trillion-parameter flagship and a 1M-token context window as the default. By introducing sparse attention and dual reasoning modes, the release delivers frontier-level agentic performance at lower compute costs.
DeepSeek, a Chinese research lab known for high-efficiency models, released the preview and open weights for DeepSeek-V4. The family includes DeepSeek-V4-Pro, a 1.6-trillion parameter Mixture-of-Experts (MoE) model (activating only some parameters per token), and a smaller DeepSeek-V4-Flash variant. Both models support a 1M-token context window as standard.
- Pro parameters
- 1.6T total / 49B active
- Flash parameters
- 284B total / 13B active
- Context window
- 1M tokens
- Reasoning modes
- Thinking and Non-Thinking
- API compatibility
- OpenAI and Anthropic
- Legacy retirement date
- July 24, 2026
This release mirrors the pattern of preview MoE models but pushes context efficiency further through DeepSeek Sparse Attention. By compressing tokens, DeepSeek is commoditizing 1M-token memory, matching optimized inference paths in standard serving frameworks. It also introduces a configurable thinking mode for deep reasoning.
Access both models via the DeepSeek API, which supports OpenAI and Anthropic-compatible formats. The models are optimized for agentic coding and integrated with Claude Code, matching the support found in open-source agent platforms. Note that legacy deepseek-chat and deepseek-reasoner endpoints will be retired on July 24, 2026.