Cognition
@cognition
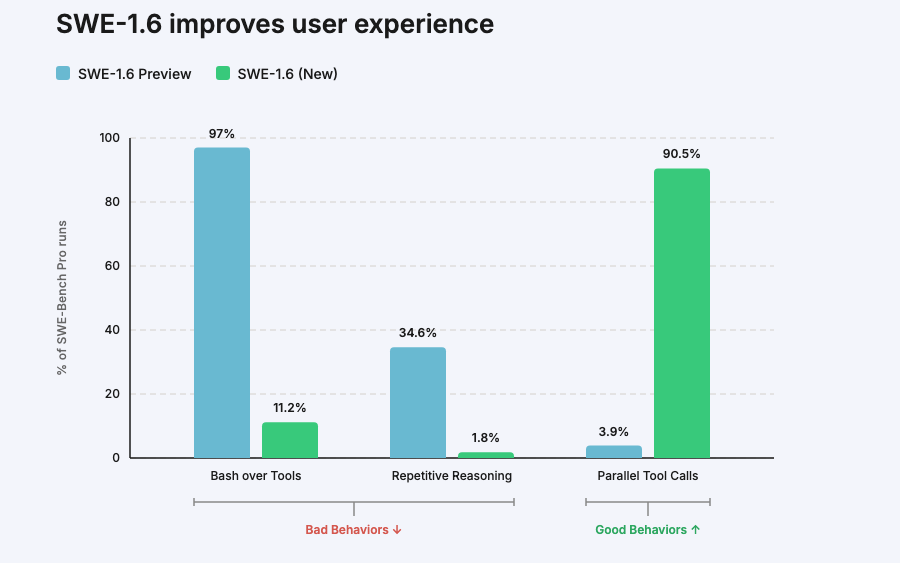
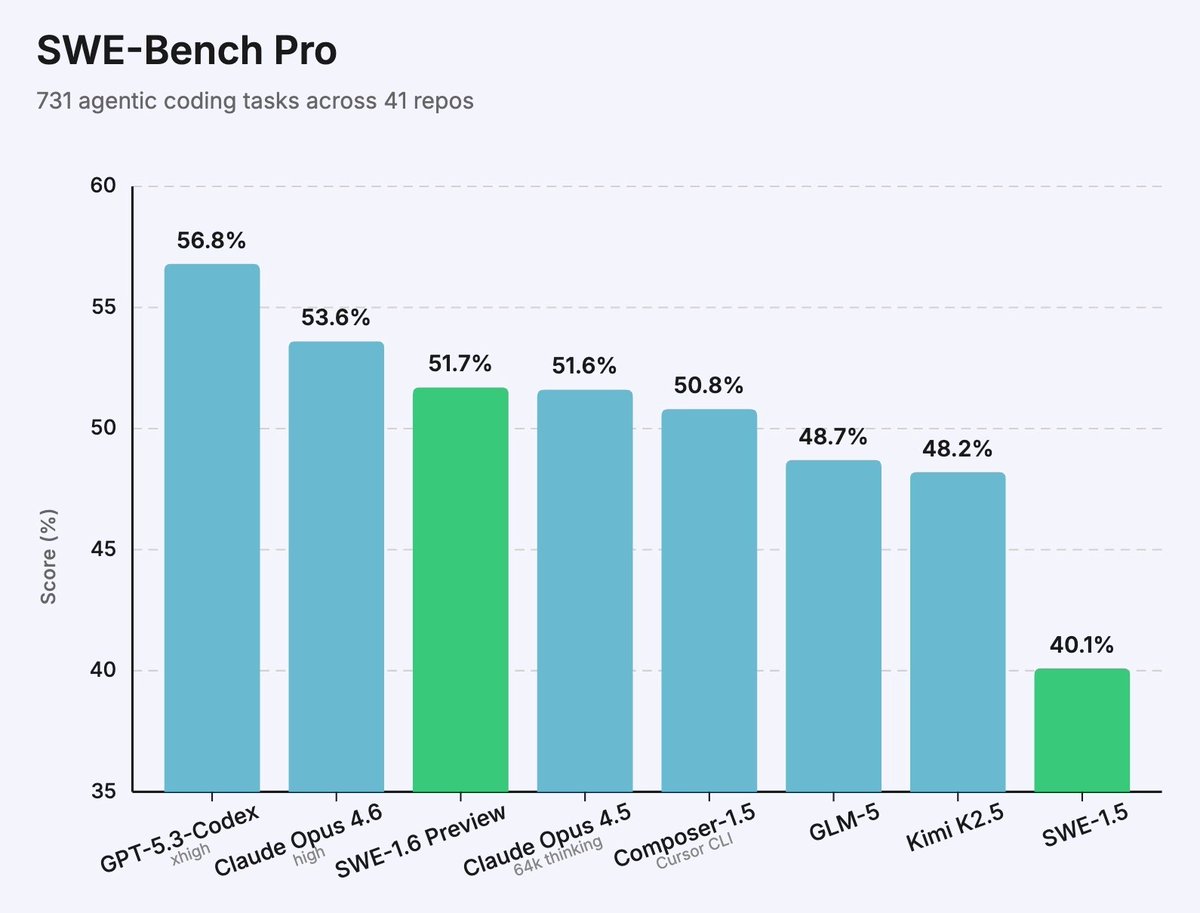
Intelligence at 1000 tokens per second, right in your terminal. Now available with SWE-1.6 Fast, powered by @cerebras. We're giving the first 100 people who respond a free month of Max to try it out. https://t.co/ExGS4bu4YB
66retweets689likes
View on X