Alibaba open-sourced Qwen3.5-397B-A17B-FP8 weights - a Mixture-of-Experts model activating only 17B of 397B parameters per token, matching frontier-model performance at a fraction of compute cost. SGLang support is merged; vLLM lands in days, making it self-hostable on standard inference infrastructure.
Qwen3.5-397B-A17B, Alibaba's latest open-weight model, combines a sparse Mixture-of-Experts architecture with Gated Delta Networks - a hybrid linear attention design replacing standard transformer attention throughout most layers. With 512 experts and only 10+1 activated per forward pass, it runs at 17B-parameter compute cost while matching the reasoning depth of a dense frontier model. Native context is 262K tokens, extensible to 1M.
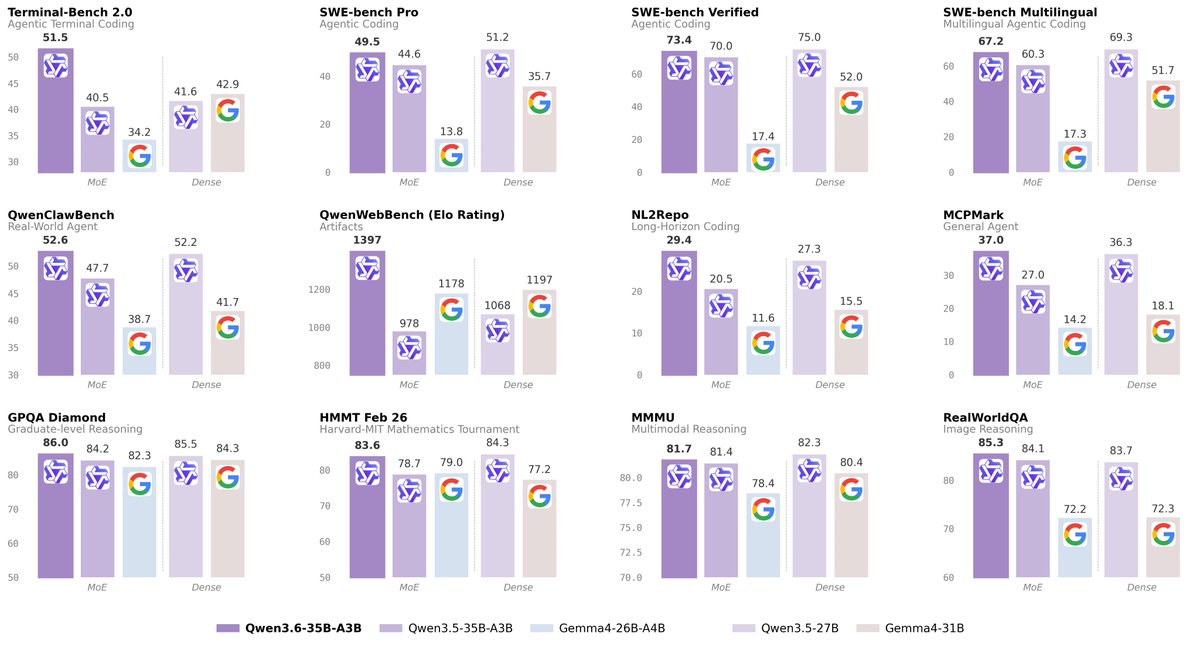
Benchmarks show it competitive with GPT-5.2, Claude 4.5 Opus, and Gemini-3 Pro across knowledge, coding, agents, and multilingual tasks - covering 201 languages. The hosted version, Qwen3.5-Plus on Alibaba Cloud, ships with 1M context and built-in tool use. The open FP8 release puts that capability in your own infrastructure.
SGLang support is merged now; vLLM support arrives in the next few days. Download weights from Hugging Face or ModelScope, check the model card for example inference code, and start experimenting.