NVIDIA AI
@NVIDIAAI
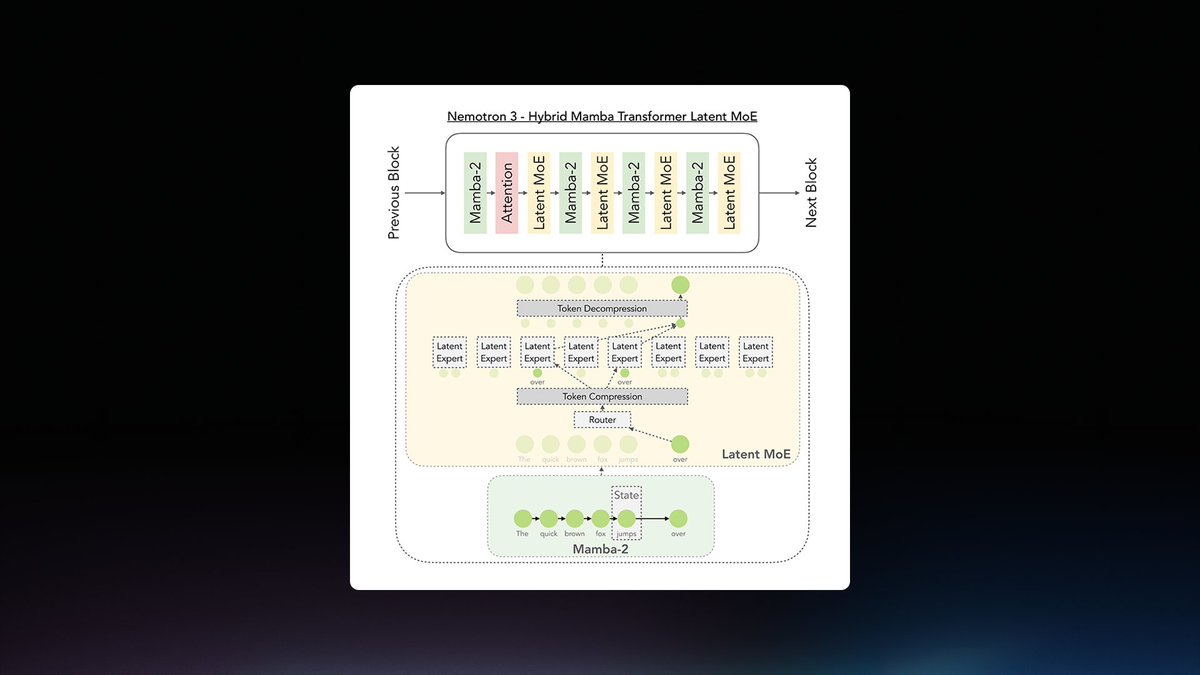
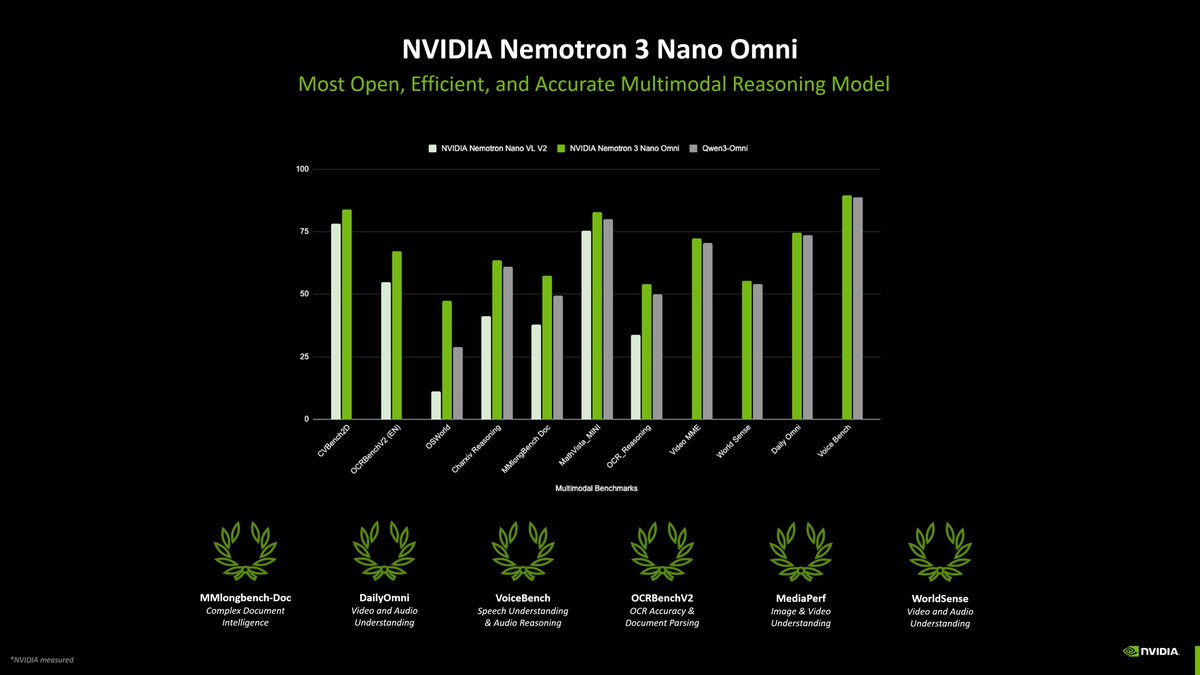
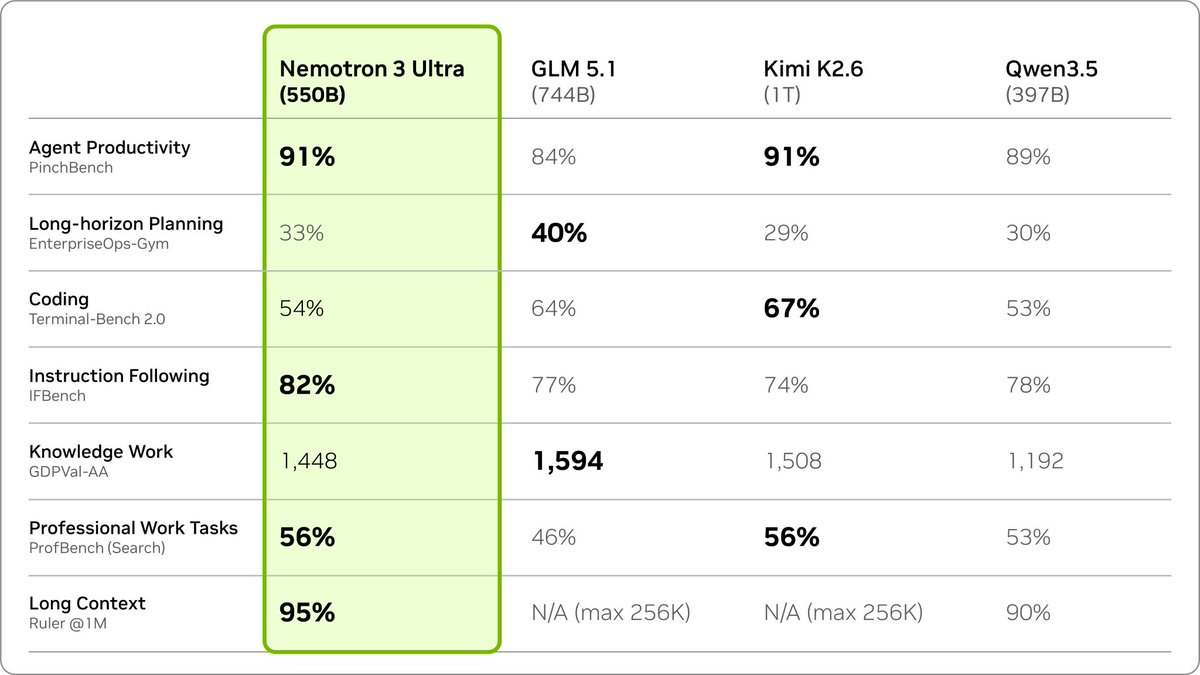
Meet Nemotron 3 Nano Omni 👋 Our latest addition to the Nemotron family is the highest efficiency, open multimodal model with leading accuracy. 30B parameters. 256K context length. 🧵👇 https://t.co/j4SPpU9SaI
93retweets711likes
View on X