AWS AI
@AWSAI
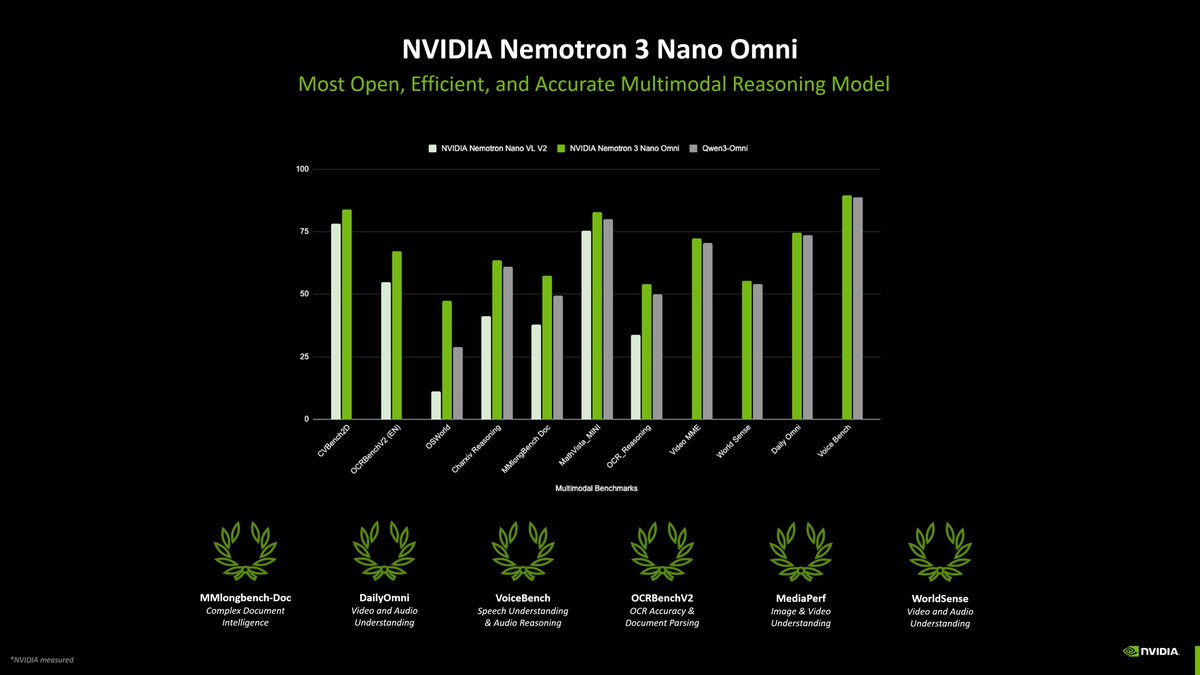
NVIDIA Nemotron 3 Nano Omni is now available on Amazon SageMaker JumpStart. This multimodal model supports video, audio, image, and text, enabling enterprise Q&A, summarization, transcription, OCR, and document intelligence. With @nvidia Nemotron 3 Nano Omni, organizations can streamline end-to-end processing of meetings, training videos, and documents. https://t.co/XgVkOg6B8x
1retweets2likes
View on X