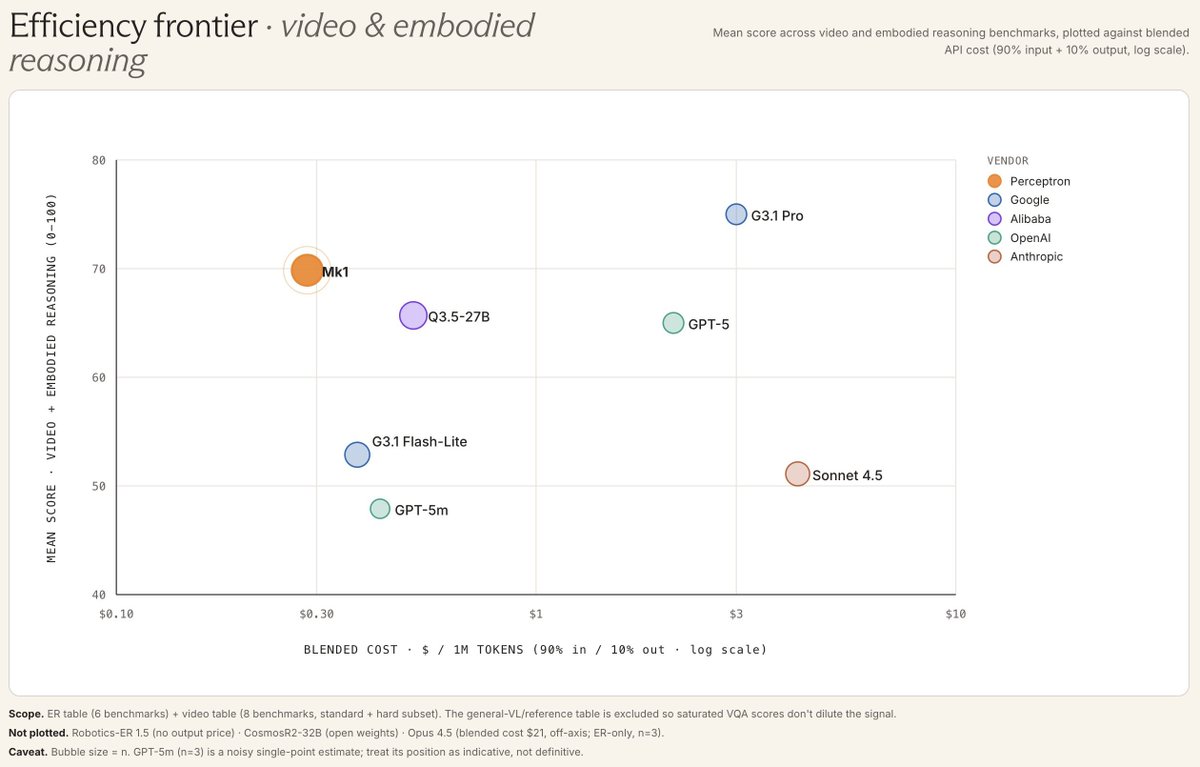
OpenRouter integrated NVIDIA's Nemotron 3 Nano Omni, a 30B-A3B model that natively processes text, audio, and video in a single inference loop. By using a hybrid Transformer-Mamba architecture, the model reduces the compute cost of video reasoning by 2.5x, making it a high-efficiency perception layer for autonomous agents.
OpenRouter, a unified API for accessing hundreds of language models, launched free access to NVIDIA's Nemotron 3 Nano Omni. This 30B-A3B Mixture-of-Experts (MoE) model (an architecture activating only a fraction of its parameters) accepts text, image, video, and audio inputs to produce text outputs.
- Model architecture
- Hybrid Transformer-Mamba MoE
- Parameter count
- 30B-A3B (30B total, 3B active)
- Context window
- 256,000 tokens
- Reasoning budget
- 16,384 tokens
- Input modalities
- Text, image, video, audio
- Pricing
- $0 per million tokens
The model uses a hybrid Transformer-Mamba architecture (a design combining attention with memory-efficient sequence modeling) to deliver 2x higher throughput than separate vision and speech pipelines. This design reduces video reasoning compute by 2.5x, matching NVIDIA's Nemotron 3 Nano Omni release and adds to OpenRouter's Tencent Hy3-Preview hosting.
Use the model as a perception sub-agent to extract context from multimodal data. It features a 256k context window and a 16,384-token reasoning budget for internal thinking. The availability mirrors the AWS SageMaker JumpStart integration, with extended thinking enabled via the reasoning parameter in the API.