Artificial Analysis
@ArtificialAnlys
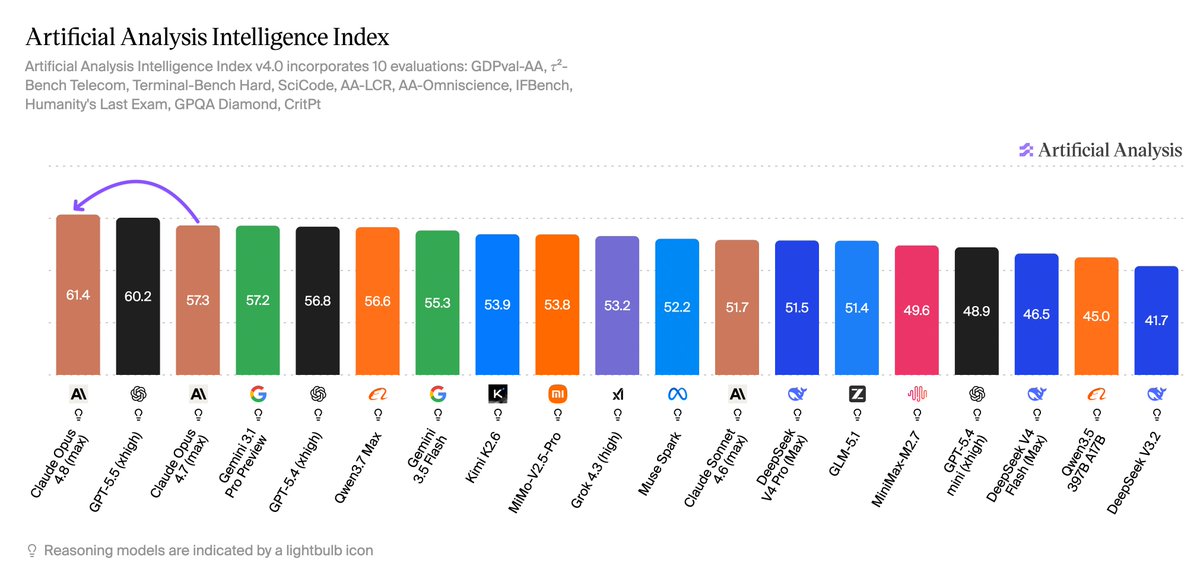
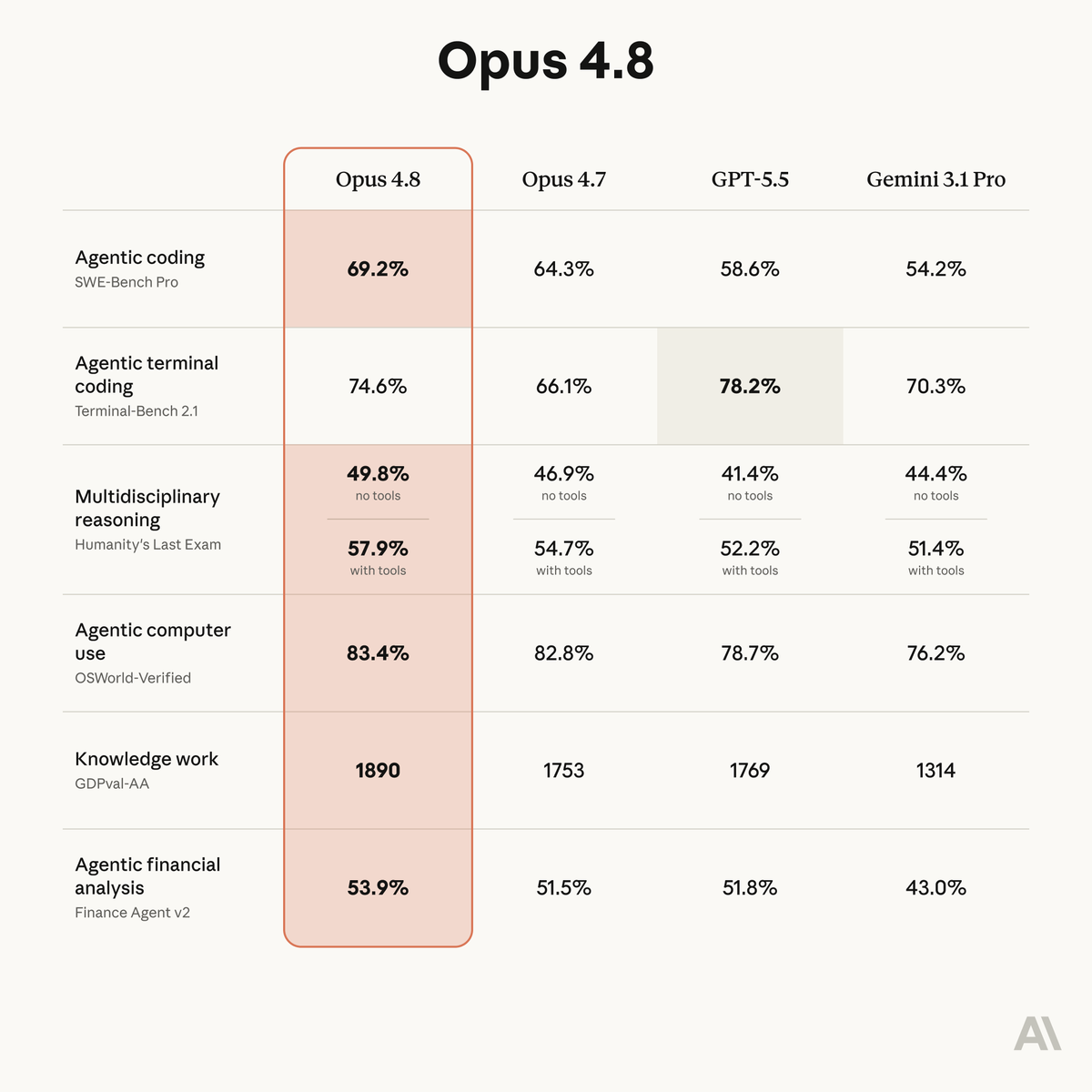
Anthropic just launched Claude Opus 4.8, and it is the new leader on our GDPval-AA benchmark for agentic real-world work tasks Opus 4.8 scored 1890 on GDPval-AA at launch with its 'max' effort setting, +137 points from Opus 4.7 and +121 points ahead of the next-best model, GPT-5.5 xhigh. Compared head-to-head on the GDPval task set, this implies a ~67% win rate against GPT-5.5 xhigh. @AnthropicAI shared access with us ahead of the public release to benchmark this model and we’re glad to see our benchmarks referenced in today’s launch. The rest of the Artificial Analysis Intelligence Index is in progress - we’ll share final results soon!
101retweets1.1klikes
View on X