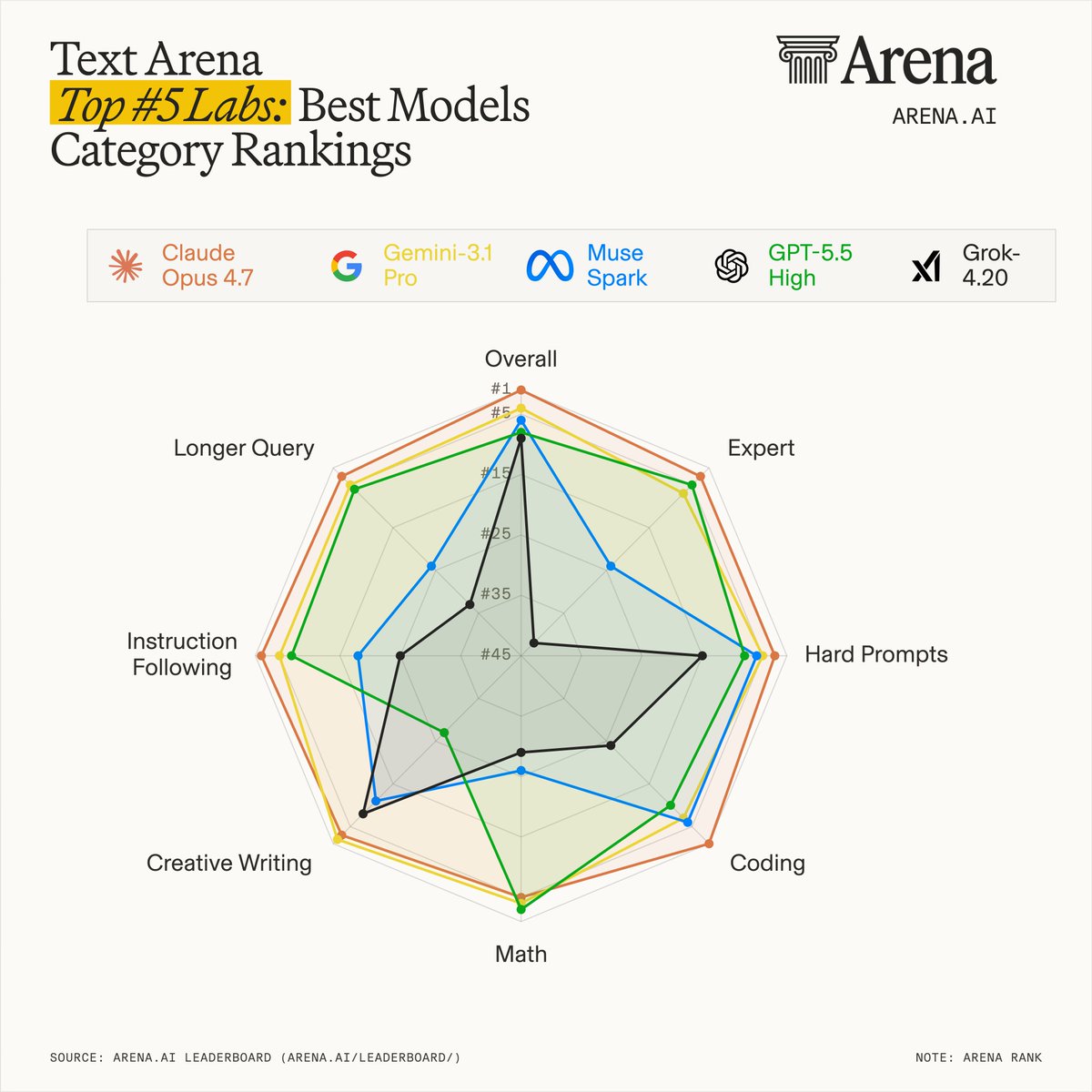
Code Arena's frontend leaderboard for models using visual inputs in agentic coding has turned over fast. Half the top 10 is new this month, with Claude setting the pace and older OpenAI and Gemini entries no longer in the top 10. - Claude by @AnthropicAI now takes all the top five. Opus 4.7 Thinking enters at #1, about 30 points ahead of Sonnet 4.6, while Opus 4.7 also lands at #3. - Claude 4.6 models mostly improved in score, but lost rank due to new 4.7 models moving the ceiling higher. - Older GPT-5.4 and GPT-5.3 Codex entries from @OpenAI are no longer in the top, while GPT-5.5 enters at #6 and #8. - Gemini by @GoogleDeepMind remains in the top 10 but has been pushed down: Gemini-3.1 Pro falls to #7, Gemini-3 Pro to #10, and Gemini-3 Flash drops out. - Qwen-3.6 Plus by @Alibaba_Qwen enters at #9, adding another new provider to the updated top 10.
Anthropic Claude Models Sweep Top Five Spots in Arena Coding Leaderboard
· Updated
Arena.ai's latest Image-to-WebDev leaderboard shows Anthropic's Claude models occupying the entire top five, with Claude Opus 4.7 Thinking taking the #1 position. The shift highlights a rapid turnover in agentic coding performance as older frontier models from OpenAI and Google fall out of the top rankings.
- #1 Rank
- Claude Opus 4.7 Thinking
- Top 5 Sweep
- Anthropic Claude models
- OpenAI Entry
- GPT-5.5 (#6 and #8)
- Google Entry
- Gemini-3.1 Pro (#7)
- Alibaba Entry
- Qwen-3.6 Plus (#9)
- Score Gap
- 30 points (Opus 4.7 Thinking over Sonnet 4.6)
This shift highlights the impact of multimodal reasoning. While Arena.ai's GPT-5.5 ranking placed it in the sixth and eighth spots, older versions like GPT-5.4 have vanished from the top 10. The dominance of "Thinking" models suggests that inference-time compute (allocating more processing power during generation) is now the primary differentiator.
For developers, these results validate Claude as the benchmark for visual-to-code workflows. Google remains in the top 10, while the Qwen3.6 Plus Arena climb secured the #9 spot. These rankings provide a verified guide for selecting models that can handle complex, multi-step frontend implementation.
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →