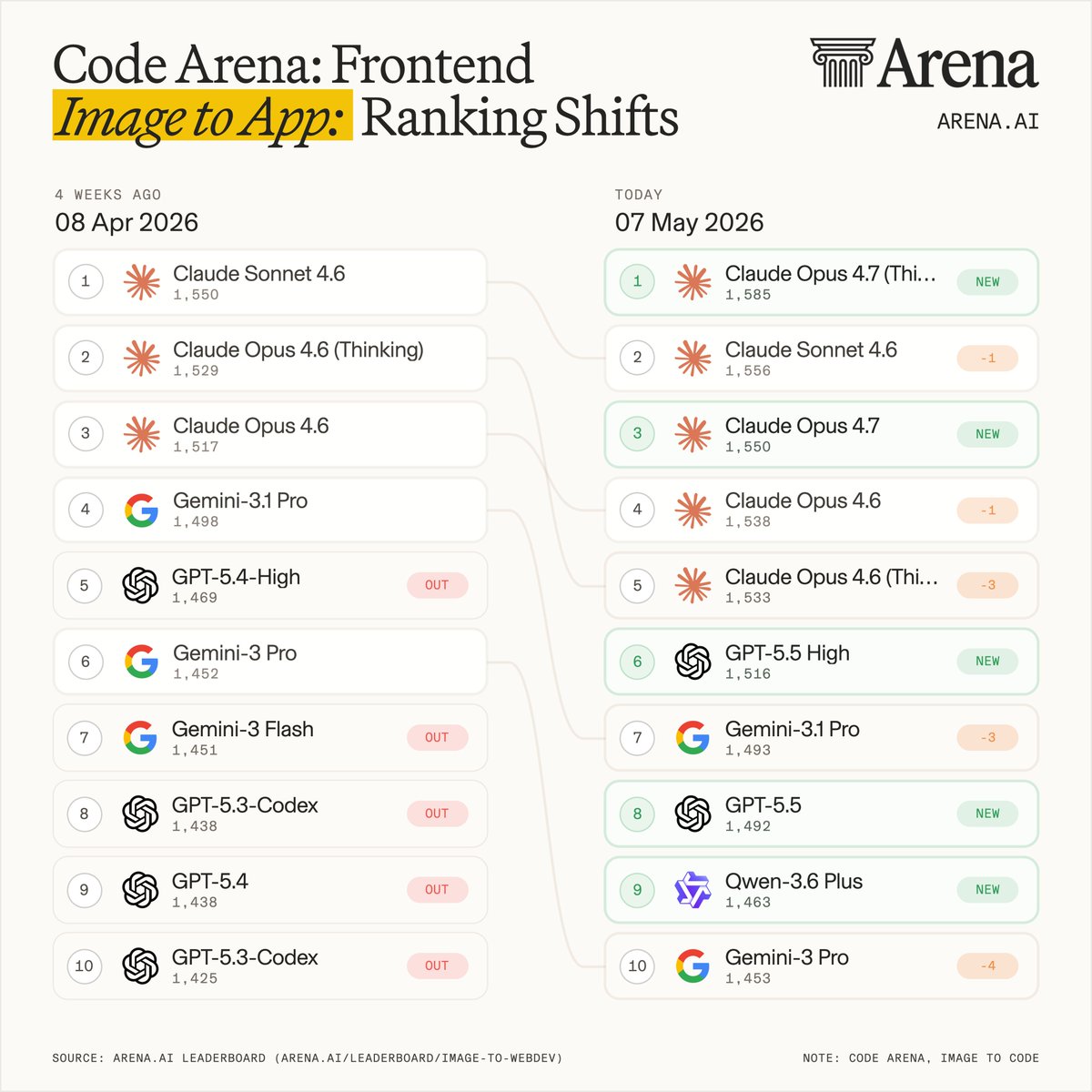
The top 5 labs in Text Arena rankings by category show that frontier models have distinct strengths and tradeoffs. #1 @AnthropicAI, Claude Opus 4.7 - The most consistently dominant model overall, leading top-tier across nearly every major category. #2 @GoogleDeepMind, Gemini 3.1 Pro - Well-rounded, with a notable edge in Creative Writing, ranked below Opus 4.7 and GPT-5.5 High in Expert #3 @AIatMeta, Muse Spark - Particularly strong in Overall and Coding, though it’s lagging behind in Expert tasks, Math, and Longer Query performance. #4 @OpenAI, GPT-5.5 High - One of the most balanced models overall, staying competitive with the top two across most categories, with especially strong performance in Expert and Math. #5 @xAI, Grok 4.20 - A more specialized profile, standing out primarily in Creative Writing and Hard Prompts, while lagging behind in Expert tasks.
Arena.ai Ranks Claude Opus 4.7 as the Most Dominant Frontier Model
· Updated
Arena.ai released its latest Text Arena rankings based on over 6 million community votes, placing Anthropic's Claude Opus 4.7 Thinking at the top of the leaderboard. The data reveals that while overall scores are tightening, models are developing specialized strengths in areas like creative writing, math, and expert-level reasoning.
claude-opus-4-7-thinking secured the #1 spot, continuing Claude's sweep of top coding rankings. The update uses 6 million human votes to identify frontier models (the most capable AI systems).- Claude Opus 4.7 Thinking Elo
- 1503
- Claude Opus 4.7 Thinking Pricing (input)
- $5 per million tokens
- Claude Opus 4.7 Thinking Context
- 1M tokens
- Gemini 3.1 Pro Pricing (input)
- $2 per million tokens
- GPT-5.5 High Context
- 1.1M tokens
Rankings highlight a shift toward specialized model personalities. While claude-opus-4-7-thinking is the only model in the top five across every category, competitors have niches. OpenAI's Arena GPT-5.5 rankings lead in expert tasks, while xAI's grok-4.20 and Google's gemini-3.1-pro excel in creative writing.
Use these rankings to select the best model for your workflow. For agentic coding, Meta's muse-spark and claude-opus-4-7 are top performers. If your tasks require deep reasoning, GPT-5.5's specialized variants are the preferred choice. Full rankings, including pricing and context window (the data a model processes at once) details, are live.
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →