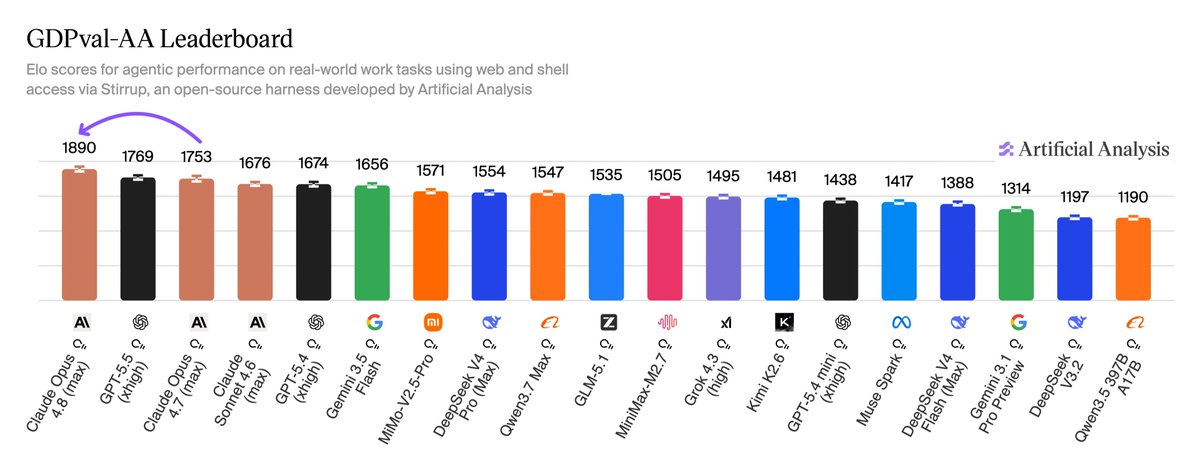
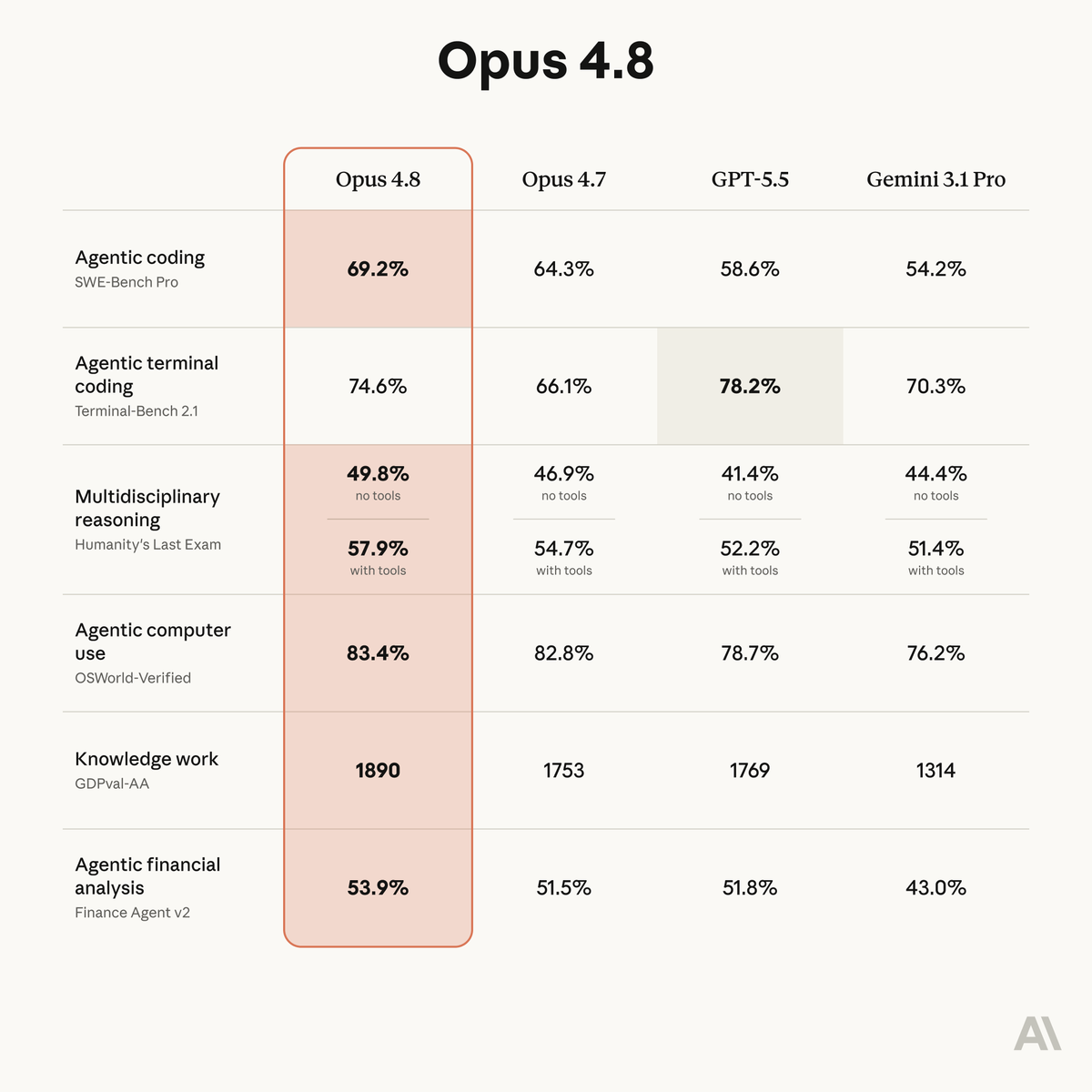
Claude Opus 4.8 takes the lead on the Artificial Analysis Intelligence Index at 61.4, with Anthropic retaking the #1 spot on GDPval-AA and advancing in terminal use and scientific reasoning To reach the leading position on the Intelligence Index, @Anthropic made large improvements in both real-world agentic work and frontier academic reasoning tasks. Key takeaways: ➤ Claude Opus 4.8 is the new leader on the Artificial Analysis Intelligence Index. Opus 4.8 scores 61.4, up +4.1 points from Opus 4.7 and +1.2 points ahead of GPT-5.5 (xhigh), the previous Index leader ➤ The new release is slightly more efficient than its predecessor on agentic tasks, but token efficiency varied by task type. We saw Opus 4.8 use fewer turns and output tokens on GDPval-AA, but approximately the same number of output tokens for the overall Intelligence Index to achieve significantly higher performance. ➤ Anthropic retakes the lead on GDPval-AA, our primary evaluation for agentic performance on knowledge work tasks. Opus 4.8 scored an 1,890 Elo, reflecting an implied win rate of approximately 67% against GPT-5.5 ➤ Claude is now among the top models for scientific reasoning. Previous releases have trailed peers on complex academic reasoning tasks, but with Opus 4.8, Claude sits slightly ahead of OpenAI and Google as the leader on Humanity’s Last Exam. It also scores higher than Gemini 3.1 Pro on CritPt, a frontier physics benchmark, but remains behind GPT-5.4 and GPT-5.5 ➤ Claude Opus 4.8 reaches #2 on AA-Omniscience, slightly ahead of Opus 4.7. Opus 4.8 scores 27.4 on the AA-Omniscience Index behind only Gemini 3.1 Pro (32.9). Accuracy ticked up slightly to 46.6% and hallucination rate held roughly flat at 35.9% - Anthropic continues to demonstrate substantially lower hallucination rates than peer models from Google and OpenAI ➤ Compared with Opus 4.7, Opus 4.8 also makes material gains on Terminal-Bench Hard (+6.8 points), τ²-Bench Telecom (+5.9 points), and IFBench (+3.6 points), with relatively flat scores across AA-LCR, GPQA, and SciCode. Other key model details remain the same as Opus 4.7: Context window of 1 million tokens (equivalent to Opus 4.7) Pricing of $5/$25 per million tokens of input/output; cache pricing remains at a 25% premium for cache writes ($6.25 per million tokens) with 5-minute time to live, and 90% discount for cache hits ($0.5 per million tokens) Effort remains the recommended way of configuring model performance and latency, with the same options as Opus 4.7 - we measured the model at its ‘max’ effort setting to test peak performance
Artificial Analysis crowns Claude Opus 4.8 as the new intelligence leader
· Updated
Artificial Analysis has ranked Claude Opus 4.8 as the new leader on its Intelligence Index, surpassing GPT-5.5 (xhigh). The model shows significant gains in agentic workflows and scientific reasoning while maintaining lower hallucination rates than its peers. This shift marks a return to the top for Anthropic in independent frontier model evaluations.
Claude Opus 4.8 at its max effort setting, finding it takes the #1 spot on the Intelligence Index with a score of 61.4. The model outperformed the previous leader, GPT-5.5 (xhigh), by 1.2 points. This ranking uses 10 benchmarks covering agentic work—AI that plans and acts independently—coding, and complex reasoning.- Intelligence Index Score
- 61.4
- GDPval-AA Elo
- 1,890
- Time to First Token
- 17.95s
- Output Speed
- 58.7 tokens per second
- Context Window
- 1M tokens
This update follows the Claude Opus 4.8 launch, which introduced self-correcting honesty and effort controls. While GPT-5.5 (xhigh) previously led in several categories, Claude Opus 4.8 now holds the lead in agentic performance for knowledge work. It also shows material gains in terminal use and scientific reasoning, overtaking Gemini 3.1 Pro in frontier physics.
The model achieves these results with improved efficiency, using 35% fewer output tokens for certain agentic tasks. However, it remains slower and more expensive than average, with a time to first token—the delay before responding—of nearly 18 seconds. These capabilities are available via the Anthropic API at $5 per million input tokens.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →