Arena.ai
@arena
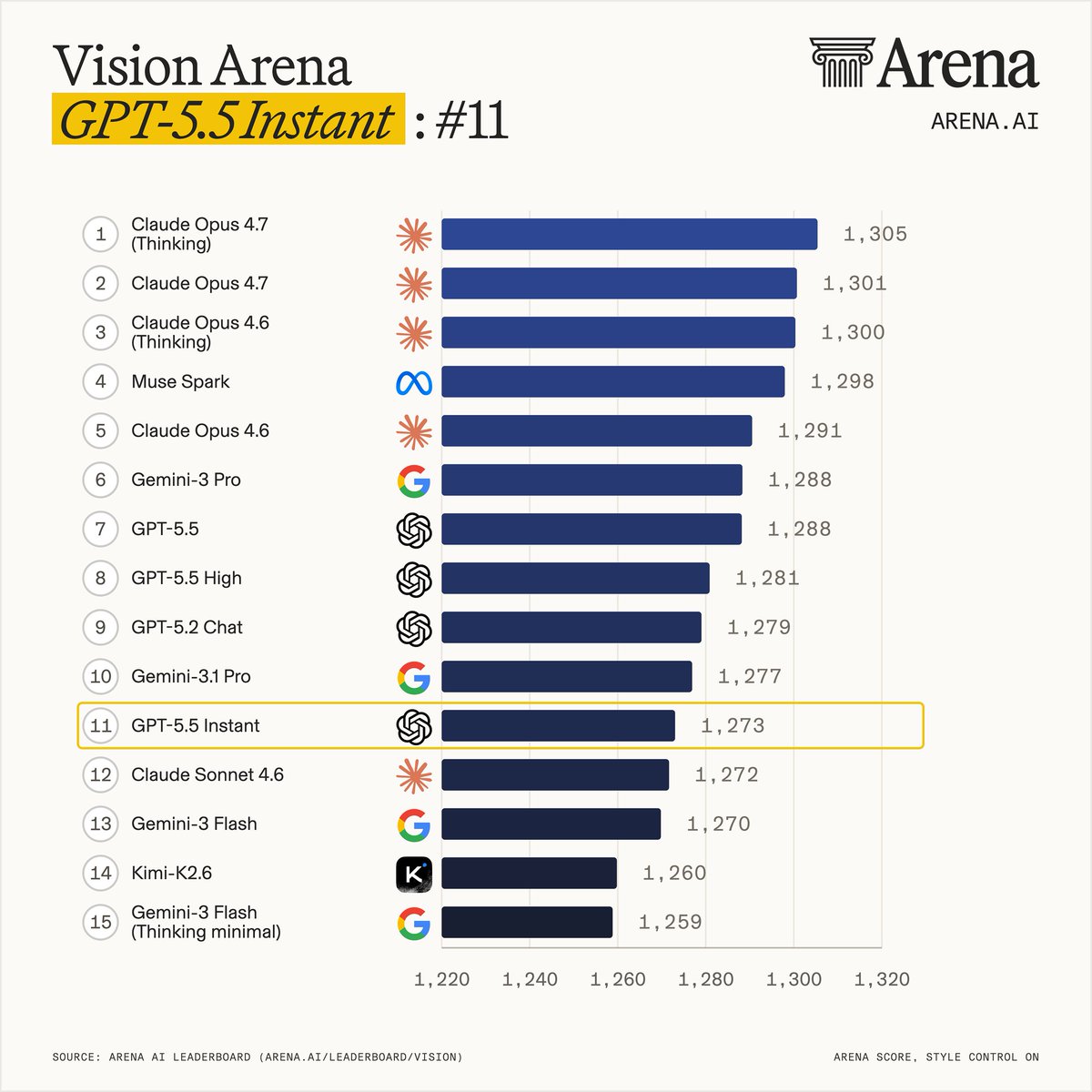
GPT-5.5 by @OpenAI is now live in the Arena, landing across multiple leaderboards. Here’s how it ranks by modality: - Code Arena (agentic web dev): #9, a strong +50pt jump over GPT-5.4 - Document Arena (analysis & long-content reasoning): #6, on par with Sonnet 4.6 - Text Arena: #7, Math #3, Instruction Following: #8 - Expert Arena: #5 - Search Arena: #2 - Vision Arena: #5 Strong, well-rounded performance, especially in Code (+50 pts vs GPT-5.4). Congrats to @OpenAI on the release. Full category breakdowns by modality in the thread.
132retweets1.9klikes
View on X