Zyphra launched Zyphra Cloud, a full-stack AI platform on AMD MI355X GPUs rather than NVIDIA, opening with serverless inference for long-horizon agents. The 288GB of memory per AMD chip — versus 192GB on NVIDIA's B200 — keeps nearly double the agent sessions resident in VRAM at long context.
Zyphra, an open superintelligence research company, launched Zyphra Cloud, a full-stack AI platform built on AMD infrastructure. The platform debuts with Zyphra Inference, a serverless service for hosting frontier open-weight models like DeepSeek V3.2 and Kimi K2.6. It is optimized for agentic workloads requiring long-running sessions and massive context windows.
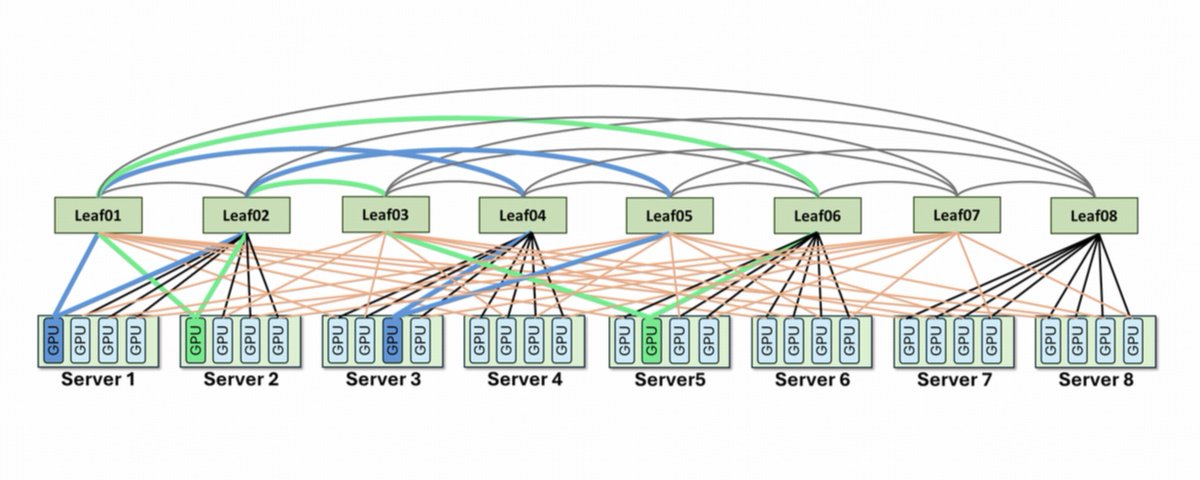
- Hardware
- AMD Instinct MI355X
- Memory per GPU
- 288GB HBM3E
- Memory per node
- 2.3TB (8-GPU node)
- Memory bandwidth
- 8 TB/s per GPU
- Initial models
- DeepSeek V3.2, Kimi K2.6, GLM 5.1
- Agent capacity
- 184 sessions (Kimi K2.6 at 256K)
As models reach trillion-parameter scales, memory capacity becomes the bottleneck for industrial-scale inference. Zyphra uses AMD Instinct MI355X GPUs, which offer 288GB of high-bandwidth memory—more than the 192GB in NVIDIA's B200. This capacity allows more user sessions to stay resident in VRAM, preventing performance-killing cache evictions when memory is exhausted.
You can access the service now to run long-context models with custom optimizations like Tree Attention. The platform supports DeepSeek, Kimi, and GLM models, with DeepSeek V4-Pro support coming soon. Sign up for the serverless API to build agents that maintain up to 256K tokens of context.