Z.ai
@Zai_org
https://t.co/jaOMnP7Yud
112retweets768likes
View on X· Updated
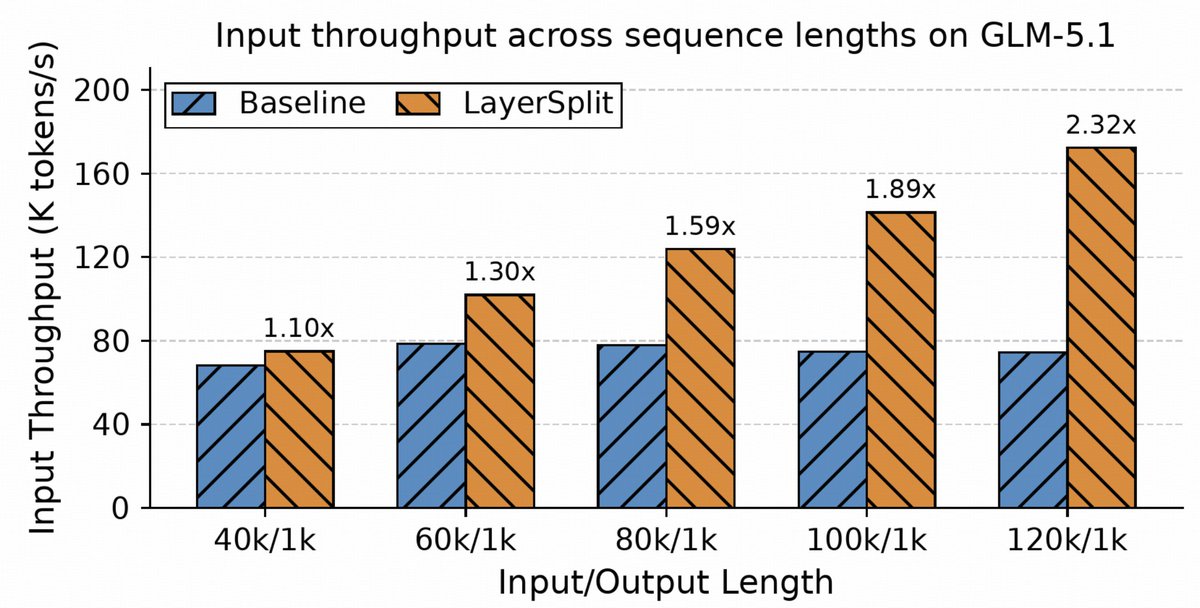
Z.ai successfully deployed its ZCube network architecture in production to power GLM-5.1 coding services, reducing hardware costs by 33% while boosting throughput. By flattening the network topology, the system eliminates the congestion typically caused by moving massive amounts of data between GPUs during long-context inference.
Modern models use Prefill-Decode disaggregation, separating prompt processing from token generation. This creates asymmetric traffic as KV Caches move between nodes. Traditional networks suffer from hotspots during these transfers, but ZCube's topology distributes traffic across a broader path space. This mirrors Moonshot AI's distributed prefill architecture by treating compute phase separation as a primary infrastructure challenge.
In production tests for the GLM-5.1 coding model, ZCube reduced hardware costs by 33% and cut tail latency by 40%. While originally a research paper, this deployment proves that hardware-layer innovation can scale to tens of thousands of GPUs. These optimizations will likely underpin future high-concurrency agentic engineering services.
https://t.co/jaOMnP7Yud
Still wondering? A few quick answers below.
Every HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →
More like this