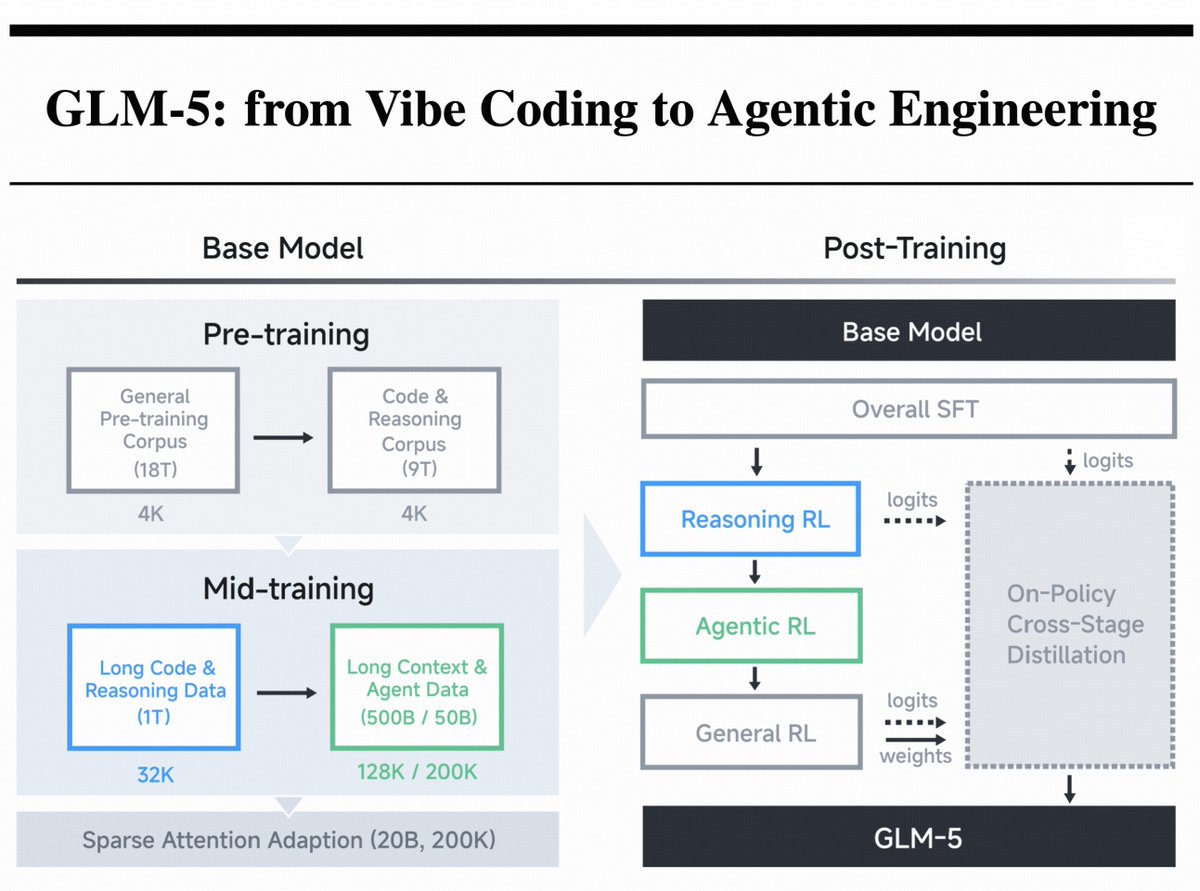
Fireworks AI added Z.ai's GLM 5.1 to its training platform, supporting supervised fine-tuning and direct preference optimization with a 200K context window. This allows developers to customize the flagship agentic model for multi-hour autonomous tasks without the numerical drift common in fragmented training and inference stacks.
Fireworks AI, an inference and training platform for fast model serving (running a trained model to generate outputs), added GLM 5.1 to its managed and API workflows. This update enables supervised fine-tuning (adapting a model to specific instructions) and direct preference optimization on the flagship model from Z.ai.
- Context window
- 200K tokens
- Training methods
- SFT, DPO, RFT
- Max model scale
- 1T parameters
- Hardware
- NVIDIA B200 clusters
- Pricing
- Per token or GPU-hour
- Availability
- Managed Training and Training API
The release follows Fireworks AI's Day-0 Kimi K2.6 support and the addition of DeepSeek V4 Pro, signaling a shift toward specialized foundries for agentic engineering. By using shared kernels, the platform eliminates numerical drift—ensuring model behavior during evaluation matches performance in production environments like Cursor or Vercel.
You can now fine-tune GLM 5.1 with a 200K context window using smart defaults or custom loss functions. This workflow is optimized for building agents that autonomously navigate codebases for up to eight hours. Managed training is priced per token, while the Training API uses per-GPU-hour pricing.