Moonshot AI launched Prefill-as-a-Service, a distributed architecture that separates the compute-heavy prefill phase from the memory-heavy decode phase across different datacenters. By using a hybrid model to shrink memory overhead, the system achieves 1.54x higher throughput and significantly lower latency for long-context requests.
Moonshot AI, an AI company building the Kimi model family, introduced Prefill-as-a-Service to enable cross-datacenter inference. This architecture separates prefill (the compute-intensive initial processing) from decode across loosely coupled clusters. It uses Kimi Linear, a hybrid-attention model that reduces KV cache (the memory state representing processed text) size by roughly 10x.
- Throughput increase
- 1.54x
- P90 TTFT reduction
- 64%
- KV cache reduction
- 10x
- Model architecture
- Kimi Linear
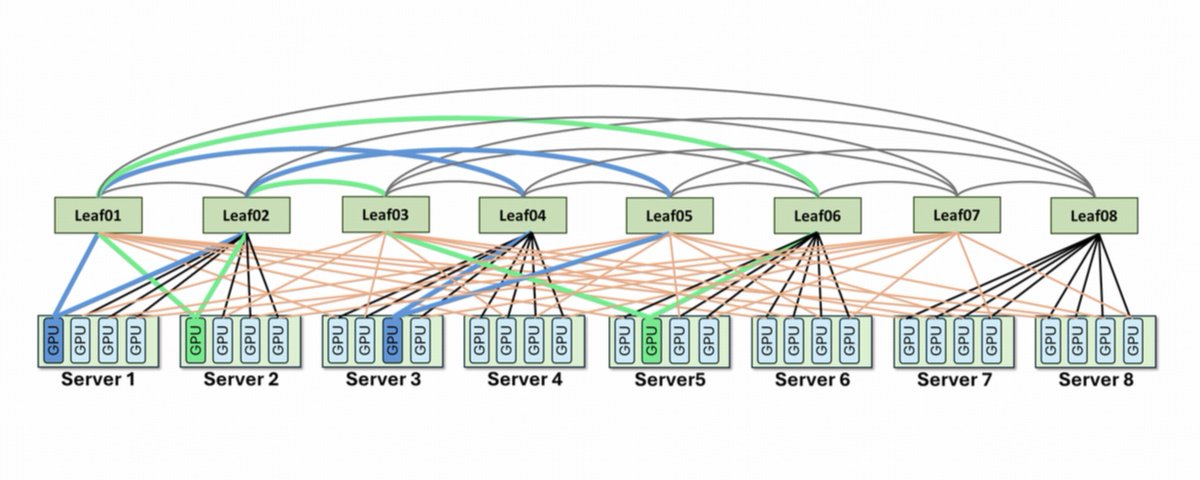
- Network requirement
- Commodity Ethernet
- Case study model size
- 1T parameters
Standard models produce massive KV caches requiring expensive RDMA networks. This bandwidth wall has historically prevented teams from using fragmented GPU capacity across regions. By shrinking the cache, Moonshot can now stream inference data over commodity Ethernet, making distributed global infrastructure a practical reality for production workloads.
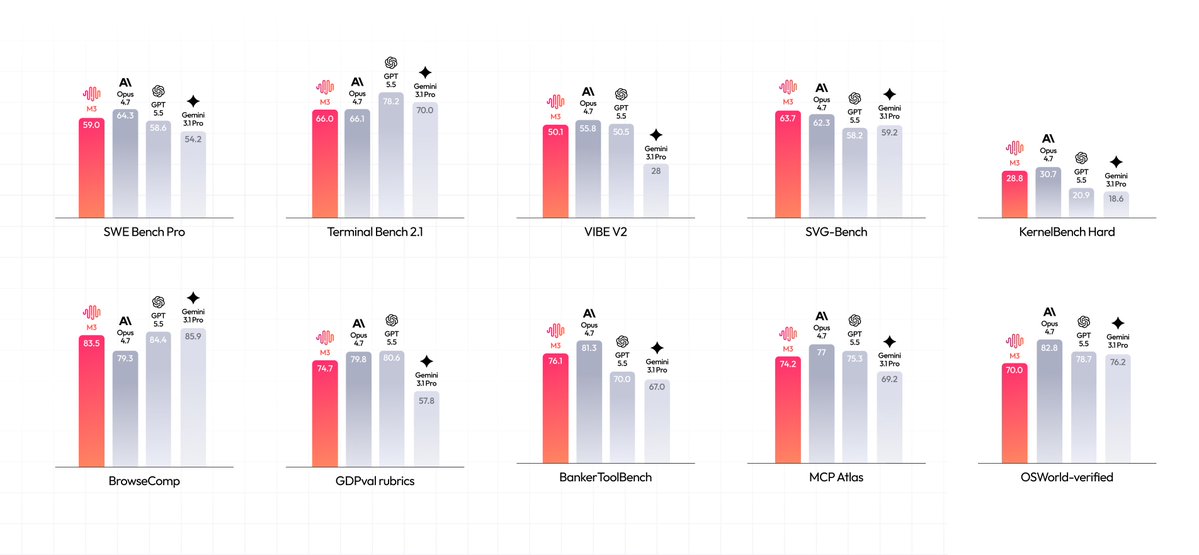
You can now scale long-context applications more efficiently by offloading heavy prefills to compute-dense clusters. In a case study with a 1T-parameter model, this approach delivered 1.54x higher throughput and a 64% reduction in P90 latency. Architectural support is expanding across open inference frameworks like vLLM and SGLang.