Z.ai
@Zai_org
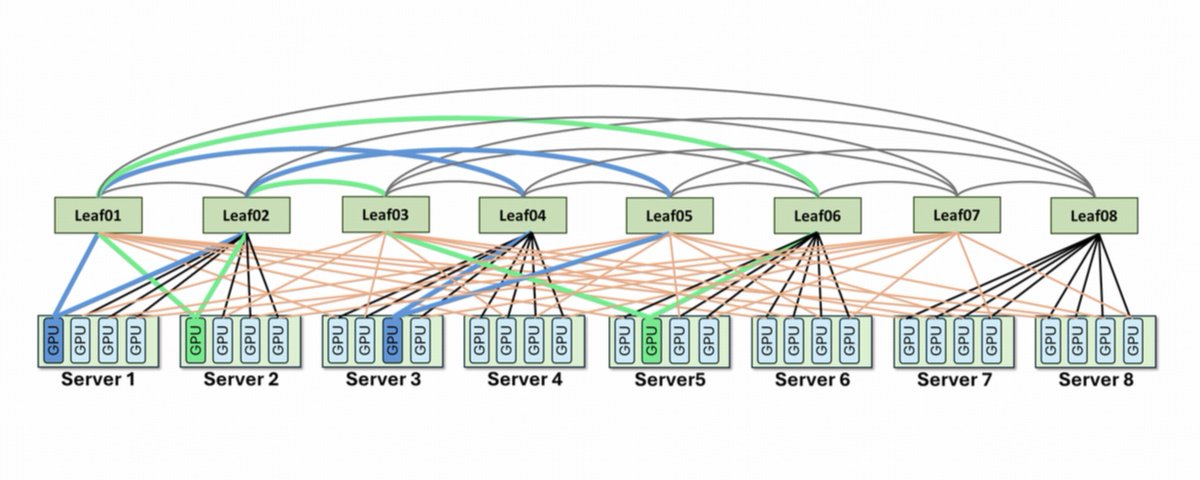
Scaling laws push model capability forward. But whether that capability becomes reliable in production depends on how we handle Scaling Pain. https://t.co/81QCQw941P In our latest blog, we share how we debugged GLM-5 serving at scale: reproducing rare garbled outputs, repetition, and rare-character generation; tracing and eliminating KV Cache race conditions; fixing HiCache synchronization issues; and introducing LayerSplit for up to 132% throughput improvement. We hope these lessons help the community avoid similar pitfalls and build more robust inference infrastructure.
45retweets475likes
View on X