Cloudflare
@Cloudflare
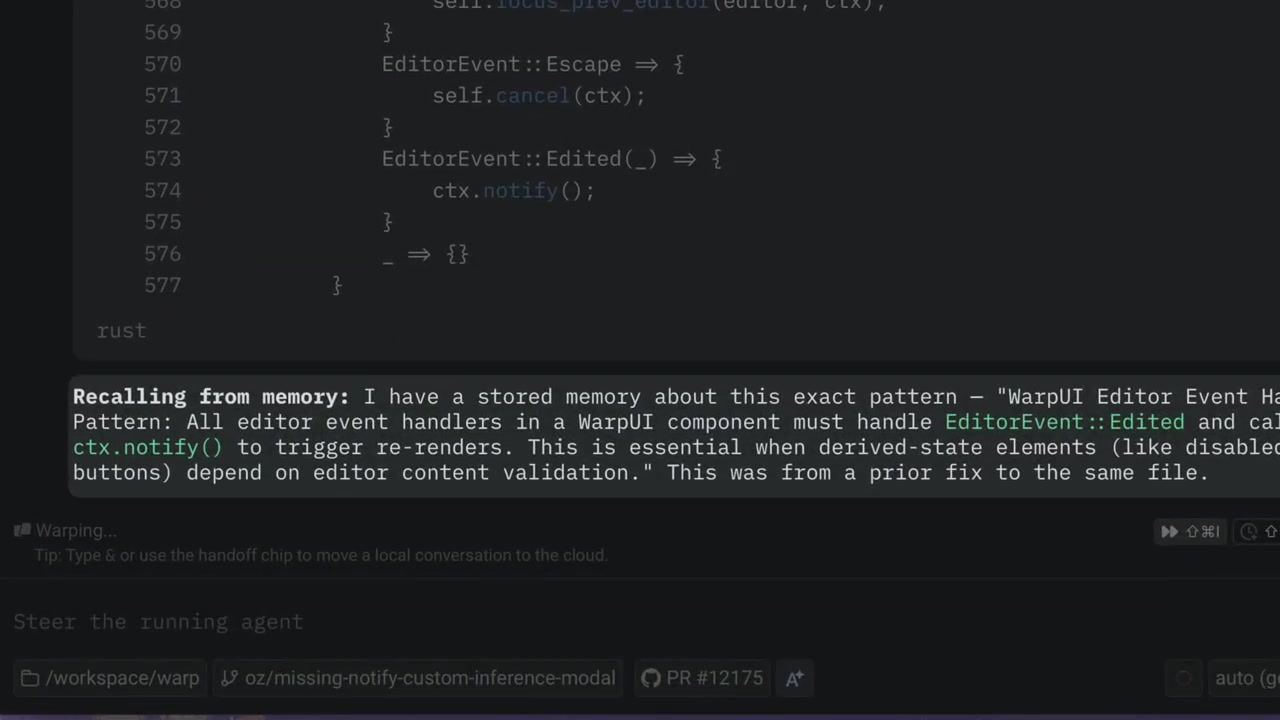
Today we're announcing the private beta of Agent Memory, a managed service that extracts information from agent conversations and makes it available when it’s needed, without filling up the context window. https://t.co/tcyjIzpiHd
46retweets412likes
View on X