Together AI
@togethercompute
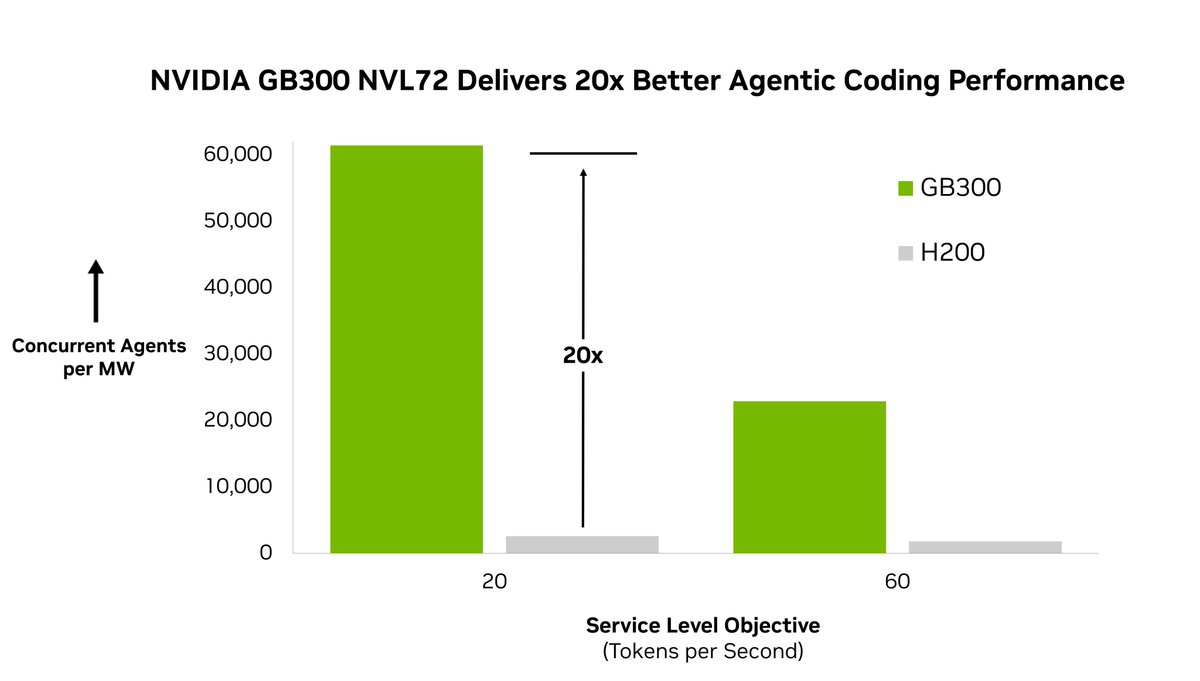
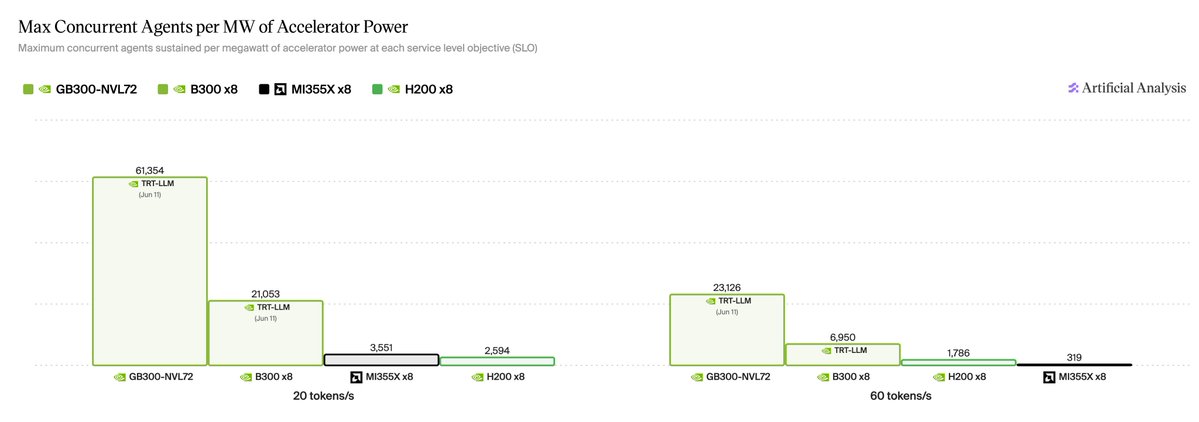
DeepSeek V4 Pro on Together AI is now #1 on Artificial Analysis for both output speed and latency. Serving V4 well is an inference systems problem: KV cache, prefix reuse, kernels, and endpoint profiles. We break down the systems work here: https://t.co/RLHi35DFif
10likes
View on X