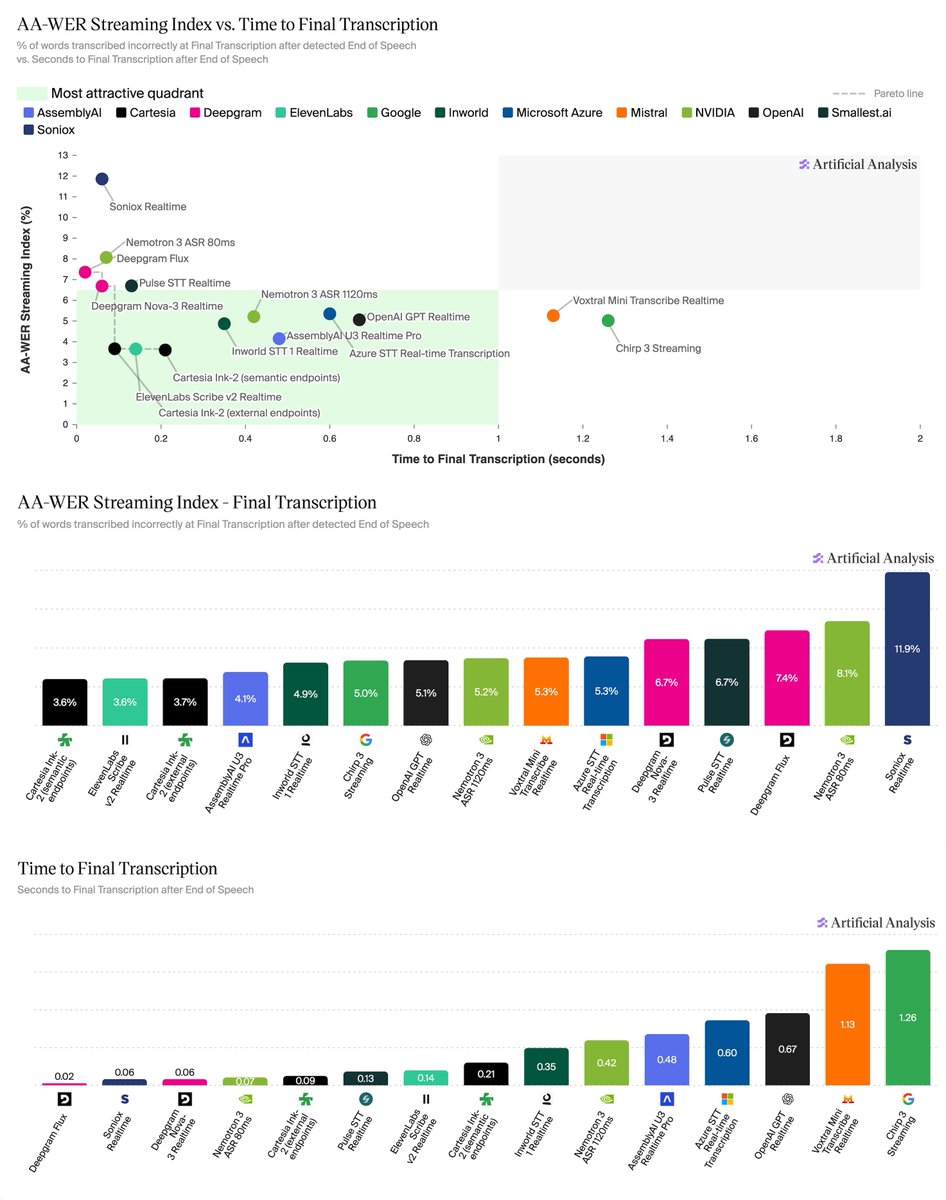
Today we're releasing the first results for AA-AgentPerf, our new agentic inference benchmark: initially covering DeepSeek V4 Pro across NVIDIA Blackwell, Hopper, and AMD. AA-AgentPerf is the first benchmark built for agentic inference. We use real, long-context agentic coding trajectory data as the workload, and inference with real production optimizations such as KV cache reuse and speculative decoding, leading to the most realistic evaluation of inference performance available today. AA-AgentPerf’s lead metric is Agents per Megawatt. In a power-constrained world, this answers the most relevant question for AI infrastructure providers - “how many real agents can I deploy per unit of power available?”. First results for DeepSeek V4 Pro (at the easiest defined service level of 20 tokens/s and 10s TTFT): ➤ GB300 (rack-scale, disaggregated): 61,354 Agents/MW ➤ B300 (single node, disaggregated): 21,053 Agents/MW ➤ MI355X: 3,551 Agents/MW ➤ H200: 2,594 Agents/MW Further AA-AgentPerf details: ➤ Real agent workloads, beyond synthetic queries: AA-AgentPerf replays real coding agent trajectories where our agents used up to 200 turns and worked with sequence lengths >100K tokens - the workloads that matter in 2026 ➤ Production optimizations allowed: KV cache reuse, speculative decoding, and prefill/decode disaggregation are all permitted, with accuracy verification to control for quality loss - we want results to reflect what real deployments actually look like ➤ Lead metric is Agents per Megawatt: simultaneous agents supported at production performance targets (e.g. 20 tokens/s per user, ≤10s TTFT) per megawatt consumed. Agents per TCO and $/hr will be supported soon Key findings: ➤ Rack-scale disaggregated inference (GB300) is ~3× more power-efficient than single-node Blackwell (B300), and similarly ahead in raw agents per GPU ➤ Blackwell represents a large generational step over Hopper in both power efficiency and raw compute per GPU ➤ In this test, NVIDIA's Blackwell systems currently lead AMD MI355X by a clear margin. Important context: our MI355X configs are approximately two weeks older than our Blackwell configs and couldn’t stably use speculative decoding. MI355X power draw under heavy load is also well below TDP, indicating there is much room to improve on DeepSeek V4 Pro, which we will measure and publish in the coming weeks ➤ Config and inference framework version matter enormously - we've seen meaningful improvements daily since the DeepSeek V4 Pro release and look forward to tracking performance over time AA-AgentPerf is a live benchmark and we publish results on a rolling basis as submissions come in. Some of the new features coming in v1.1: more models (gpt-oss-120b), more hardware (GB200, B200, H100, MI300X), better AMD configurations, $/hr and cost-per-task normalization, Agents per TCO, and performance tracking over time.
Artificial Analysis Launches AA-AgentPerf Benchmark for Agentic Inference Workloads
Artificial Analysis launched AA-AgentPerf, the first benchmark measuring agentic inference performance using real coding trajectories. The benchmark’s lead metric, Agents per Megawatt, evaluates concurrent agent capacity at production service levels. Initial results for DeepSeek V4 Pro show NVIDIA’s rack-scale GB300 system sustains 61,354 agents per megawatt, significantly outperforming single-node Blackwell and Hopper configurations in power efficiency.
Artificial Analysis
@ArtificialAnlys
25retweets277likes
View on XEvery HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →