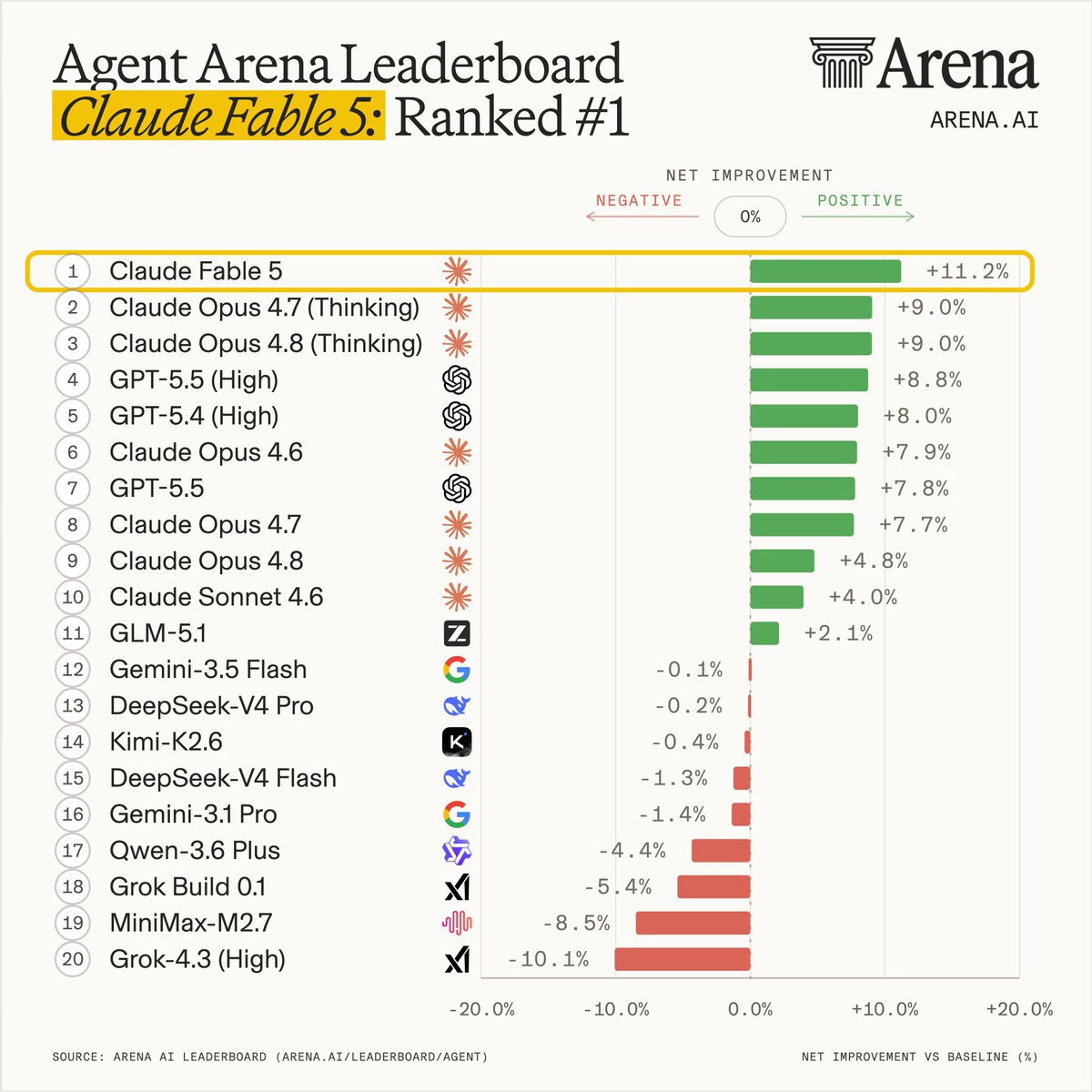
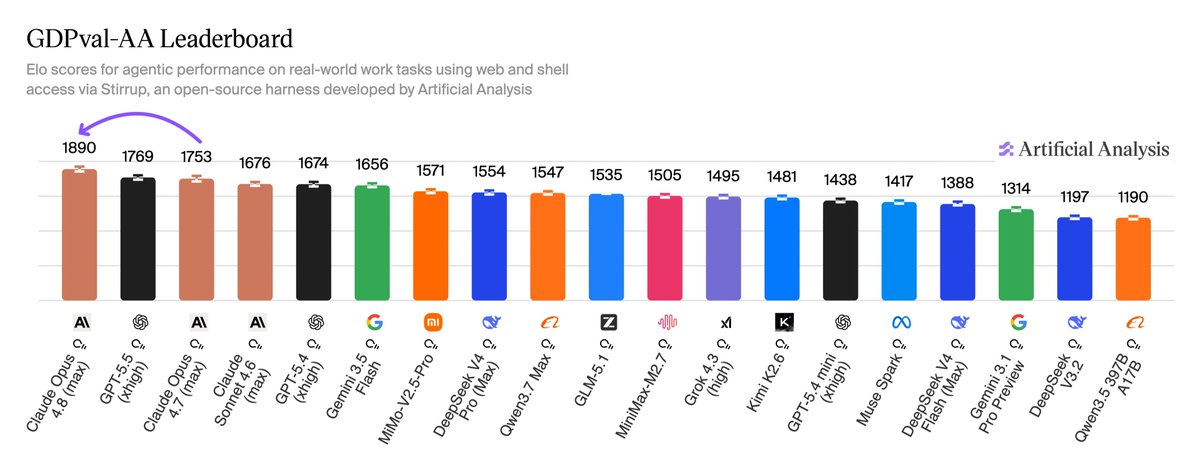
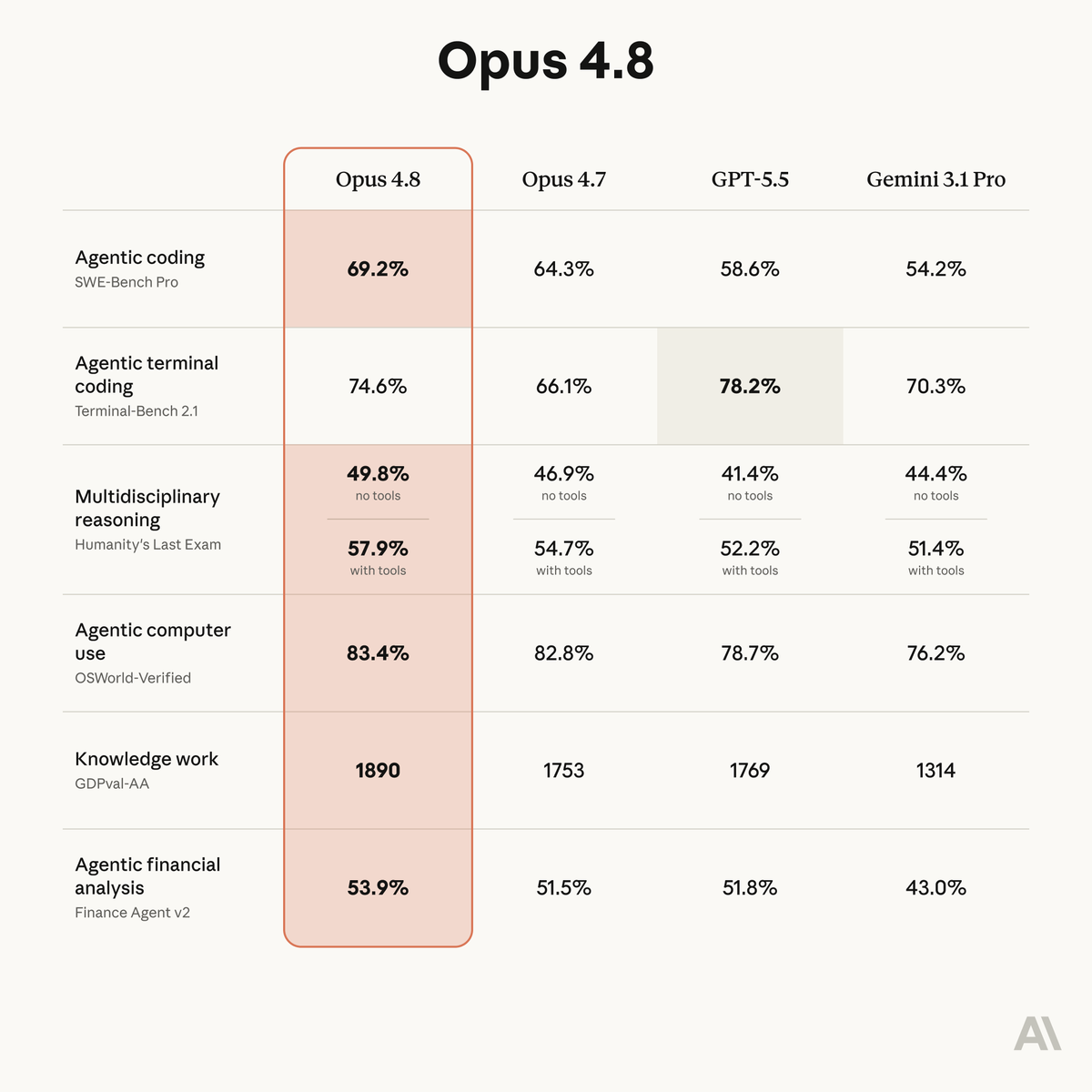
Claude Opus 4.8 debuts on Agent Arena tied #1 with GPT 5.5 (High) for Thinking & ranked #8 for Non-Thinking. The Opus 4.8 models show a small improvement over their predecessor 4.7 specifically when thinking is turned on. With thinking on, it completes more tasks than 4.7, but comes in slightly less steerable and slower to recover from bash errors. This variant also regresses on tool hallucination. With thinking off, it logs one of the highest tool hallucination rates on the leaderboard. Agent Arena ranks models on real-world agentic tasks using a causal tracing methodology. A model’s net improvement indicates how it compares to the average model. The thread breaks down how the two Opus 4.8 variants from @AnthropicAI scored across 5 signals, drawn from real tasks submitted by a global community of users.
Arena.ai Adds Claude Opus 4.8 to Agent Arena Leaderboard
Arena.ai added Anthropic's Claude Opus 4.8 to its Agent Arena leaderboard. With thinking enabled, the model ties for first place with a 9.1% net improvement in task completion. However, the model shows regressions in steerability and bash recovery, while the non-thinking variant logs one of the highest tool hallucination rates on the platform.
Arena.ai
@arena
21retweets381likes
View on XEvery HeadsUpAI update is written based on its original source and reviewed before it's published. Read our editorial standards →